
Mathias Magnusson
Let’s talk about ORDS VII

This post is part of a series that starts with this post.
Having gone through much of what can be done with a basic REST-service earlier in this series, it is time to look at securing the service. When you can access a service with noting noire than just the URL, then so can anyone else that has access to sen toe ORDS-server the URL. Not only can they read, but if the view allows writing then they can do that too as an autoREST view has DML capability too in the generated API.
In the example used for this series it will not work as the view goes against a view Oracle has defined and that cannot be updated by you as a user. However, you will typically want to protect read as well as write for your services. That is what we’ll achieve with securing the service. In this post we’ll secure it from access and in the next we’ll look at accessing the secured service.
To secure a service we create a role, and a privilege and then define what it will protect, in our case we’re protecting a path in the URL.
Let’s start with creating a role. It is done by just giving it a name, nothing else is needed.
Remember, we protect the service in the source database/schema. That is rest_demo with the alias rest_demo_schema in the setup for this series.
exec ords.create_role(p_role_name => 'gnome_role');Why gnome you ask? Well, there is a certain theme to the images in this series.
Now, the next step is to set up a privilege that is used to protect the service.
begin
ords.create_privilege(
p_name => 'gnome_priv',
p_role_name => 'gnome_role',
p_label => 'Gnome Data',
p_description => 'Give access till demo data.');
end;
/With that all there is left is to define what it should protect. With an AutoREST-enabled view our only option is to define a path for the URL to protect.
begin
ords.create_privilege_mapping(
p_privilege_name => 'gnome_priv',
p_pattern => '/vw_rest_svc/*');
end;
/With that the service on that path is now protected. Note that the pattern is within the schema-alias. It starts from that point in the URL so it does not work to have /ords/… That is good as it allows the alias for the schema to be changed without the security being side stepped.
All that is left now is to verify that the service is in deed not available anymore.
curl https://.../ords/rest_demo_schema/vw_rest_svc/ | python3 -m json.tool {
"code": "Unauthorized",
"message": "Unauthorized",
"type": "tag:oracle.com,2020:error/Unauthorized",
"instance": "tag:oracle.com,2020:ecid/039ed419abad226de418d37c6f146756"
}
Great, the service is now protected. In fact, it is so well protected that there is no way to access it. Setting up to allow access is where we pick up in the next post.
Let’s talk about ORDS VI

This post is part of a series that starts with this post.
It is time to turn to query parameters. It expands on the end point to allow slicing and dicing what we get back. Or in other words it allows projection. Or in layman terms, you can supply a where-clause expressed in jSON. You can also define sorting and much more.
query parameters are basically key-value pairs with an equal sign as the separator. THis sounds much more academic and complex than it is in reality.
Our tests will all have the end-node as its base. That is for our test-case https://.../ords/rest_demo_schema/vw_rest_svc/. All query parameters are added after that.
The default for number of rows returned is 25 as we have seen in most of the previous posts. But let’s change that for a single call and get just the first row. Add limit=1 to the url, We need to start with a question mark to indicate that the http-string now continues with parameters. I prefer to use cURL as it is as bare bones as one can get with http-calls. Remember the python module used for formatting so it get’s easier to read? All of that means that the call would look like this.
curl https://.../ords/rest_demo_schema/vw_rest_svc/\?limit=1| python3 -m jsonNote that dues to Linux shell mechanics the question mark has special meanings so I have to escape it by putting a backslash before it. That is only needed on the prompt in Linux so remove it in the web browser or database.
Skip some rowsNext up, let’s skip three rows in the result set and get one. Run the REST-call without any parameters to see all rows so you can verify that the result is correct. Add \?offset=3\&limit=1 to the end node. Note that ampersand also has special meaning so on the prompt you need to escape it also. Look att the next and prev URLs, they are now using the limit you sent in so using them you get the same amount of data for every call you make using those.
How about sorting data by the name of the objects? Just add $orderby to the end node. This one is a bit more complex as in has another key-value pair as its value. {$orderby:{object_name:ASC}} says that we want to sort by the object_name in ascending order. We’ve now gotten enough complexity with our command that we need to url-encode the parameter for curl to not interpret it and cause errors.
curl --get https://.../ords/rest_demo_schema/vw_rest_svc/ \
--data-urlencode 'q={"$orderby":{"object_name":"ASC"}}' \
| python3 -m json.toolWe specify that GET is the method to use and we request URL-encoding of the parameterstring. curl will replace special charaters with %-encoded values. It then concatenates that to the URL and puts a questionmark before it.
The result is 25 rows (as per the default) where the result is sorted in ascending order, thus the result are objects starting with the letter A.
Sorting + Limit + OffsetTaking the above in and combining them to allow limiting number of rows from a sorted result and skipping the first n rows.
We’re using both –data-encode and –data as the parameter values in –data does not have to be encoded. It cannot be padded onto the string we add to –data-urlencode as it will encode & to encoded values.
curl --get https://.../ords/rest_demo_schema/vw_rest_svc/ \
--data-urlencode 'q={"$orderby":{"object_name":"ASC"}}' \
--data '&limit=1&offset=3' | python3 -m json.toolThe result is the fourth row sorted by object_name.
Sorting + Condition + LimitNext up is a similar variant, only now we want to define the start for the search with a where-clause like condition rather than skipping over a number of rows.
curl --get https://.../ords/rest_demo_schema/vw_rest_svc/ \
--data-urlencode 'q={"$orderby":{"object_name":"ASC"},"object_name":{"$between":["AD","Z"]}}' \
--data '&limit=1' | python3 -m json.toolI use between here to achieve a greater than check. I have not found another filter-criteria that achieves that for strings. For number there is “column”:{“gt”:12345} which is more natural looking for when there is no upper bolunds of interest.
The result is that the same row is returned as with the previous example.
Doing it with PL/SQLWe can of course use the same query parameters with PL/SQL.
set serveroutput on
set define off
declare
payload clob;
svc varchar2(200) := 'https://.../ords/rest_demo_schema/vw_rest_svc/';
begin
dbms_output.put_line('Base:');
payload := apex_web_service.make_rest_request
(
p_url => svc
, p_http_method => 'GET'
);
dbms_output.put_line(payload);
dbms_output.put_line(null);
dbms_output.put_line('Limit:');
payload := apex_web_service.make_rest_request
(
p_url => svc || '?limit=1'
, p_http_method => 'GET'
);
dbms_output.put_line(payload);
dbms_output.put_line(null);
dbms_output.put_line('Limit and Offset:');
payload := apex_web_service.make_rest_request
(
p_url => svc || '?offset=3&limit=1'
, p_http_method => 'GET'
);
dbms_output.put_line(payload);
dbms_output.put_line(null);
dbms_output.put_line('Sorting:');
payload := apex_web_service.make_rest_request
(
p_url => svc || '?q={"$orderby":{"object_name":"ASC"}}'
, p_http_method => 'GET'
);
dbms_output.put_line(payload);
dbms_output.put_line(null);
dbms_output.put_line('Sorting + Limit + Offset:');
payload := apex_web_service.make_rest_request
(
p_url => svc || '?q={"$orderby":{"object_name":"ASC"}}'
|| '&offset=3&limit=1'
, p_http_method => 'GET'
);
dbms_output.put_line(payload);
dbms_output.put_line(null);
dbms_output.put_line('Sorting + Limit + Condition on PK:');
payload := apex_web_service.make_rest_request
(
p_url => svc || '?q={"$orderby":{"object_name":"ASC"},'
|| '"object_name":{"$between":["AD","Z"]}}&limit=1'
, p_http_method => 'GET'
);
dbms_output.put_line(payload);
dbms_output.put_line(null);
end;
/That block of code executes the same exact calls as previously done with cURL, and it of course then has the same exact result.
The paging and offset we’ve used poses some challenges when there are lots of data. Each call will read the same rows and just skip over more and more. For such cases you will want to page by using a filter-condition.
Having looked at how the data can be retrieved using query parameter, we’ll take a look at securing the service in the next post.
Let’s talk about ORDS V

This post is part of a series that starts with this post.
In the last post we covered how to get the JSON-data returned from a REST-call converted back over to be represented as the rows and columns we are used to work with in the database. We’ll now take a look at how paging works and how we work with it to get a view to read all the rows.
Let us first revisit how one reads one chunk of data after another. The default is to get 25 rows in each call. If we look at it with cURL again we can get the first 25 by just referencing the end-point for our service.
curl https://.../ords/rest_demo_schema/vw_rest_svc/ | python3 -m json.tool As usual the python part just makes it more readable. You can run just the cURL-command without it and look for the next-url. The next-url will look something like this.
{
"rel": "next",
"href": "https://.../ords/rest_demo_schema/vw_rest_svc/?offset=25"
}
If you take the href-value and use it in a cURL-call you get the 25 next rows and you get a new next-url that ends with offset=50. Offset tells the service how many rows from the beginning to skip over before starting to return data. Thus to get all the rows you have to loop and call the next-url until there is no more. If there is more data, the hasMore attribute in the JSON-response will have the value true and if not it has the value false. Thus, loop until hasMore is false and grab all the rows that gets returned in all the calls.
That is exactly what we’ll do with PL/SQL to let us replicate using REST for a database link. We will then have just a view that get’s the user the needed data without them having to even know that we’re using REST.
We start with the infrastructure piece. That is the part that reads the REST-view repeatedly until all rows has been read. we do this from the target schema ( and database) rest_demo_caller.
create or replace package resttest as
type payload_r is record (rsp clob);
type payload_l is table of payload_r;
function page_data return payload_l pipelined;
end resttest;
/We need a type we can return (pipe) to a SQL. In this simple case we have only a CLOB in the record that then is set up as a type that is a table. The function has no parameters in this example and it returns data pipelined so it can be the source in a SQL.
The implementation is pretty straightforward also.
create or replace package body resttest as
function page_data return payload_l pipelined is
payload payload_r;
payload_json json_object_t;
next_url varchar2(255) :=
'https://.../ords/rest_demo_schema/vw_rest_svc/';
more_data varchar2(5) := 'true';
begin
while more_data = 'true' loop
payload.rsp := apex_web_service.make_rest_request
(
p_url => next_url
, p_http_method => 'GET'
);
pipe row(payload);
payload_json := new json_object_t(payload.rsp);
next_url := treat(payload_json.get_array('links')
.get(3) as json_object_t).get_string('href');
more_data := payload_json.get_string('hasMore');
end loop;
end page_data;
end resttest;
/Even if it is straightforward, it may not be obvious what and why so let’s go through the different parts.
On line 4 the payload is declared as a record of the type we declared in the package spec. It will hold the json that is returned from the REST-call.
Line 6 declares payload_json which will be used to deal with thye json-response using json-functions.
Line 8 declares next_url that holds the URL we’ll send in the rest -call.
Line 11 more_data stores the value for hasMore from the last REST-call.
In the begin-end (12-29) everything is a loop on more_data checking if there is yet more data to be fetched.
Line 14 makes the actual REST-call lacing the returned JSON in payload.rsp.
Line 20 is where the record is piped out to the calling SQL.
Line 22 takes the JSON and puts it into a parsed JSON-object. It may look strange if you are new to object-notation syntax. But it creates a new object, nothing more.
Line 23 is a bit complex, but all it does is to navigate the JSON-document. It begins with grabbing the “links” array, in there it takes the fourth element (which is a record) and returns the value for “href”. In plain english it takes the value of the next-url and puts it into the next_url variable. Why does it take the fourth element? PL/SQL starts arrays at 1. True, but this is JSON so it stays true to JSON rather than PL/SQL.
Lastly on line 26 the attribute hasMore is pulled out to the variable more_data. This is so the loop ends when there is no more data to read from the rest-service.
Now we have a function that will return one JSON-document after another from the REST-service as long as we keep fetching them and there is more data to be had. To get this data converted to rows (each JSON-doc has 25 rows) we can use a SQL that looks like the one we used in the last post.
select object_id
, owner
, object_name
from table(resttest.page_data) t
cross join json_table (t.rsp, '$.items[*]'
columns ( object_id number path '$.object_id'
, owner varchar2 path '$.owner'
, object_name varchar2 path '$.object_name')) jThis is more or less identical with the SQL in the last post with a couple of changes. The select in the beginning of the FROM-clause has been replaced with a call to the function we just defined. This is to keep getting more and more data. The other one is that the first parameter in json_table is now t.rsp. “t” is the same as it is the alias for the data from the REST-call. But rsp used to be response, it changed due to how the column in the record was named.
With this in place we can now create a view based on this sql to allow us to select the data we want using a plain SQL.
create view the_view as
select object_id
, owner
, object_name
from table(resttest.page_data) t
cross join json_table (t.rsp, '$.items[*]'
columns ( object_id number path '$.object_id'
, owner varchar2 path '$.owner'
, object_name varchar2 path '$.object_name')) j
;You can now give a user access the the view “the_view” and they can get the data using this simple SQL.
select * from the_view;OBJECT_ID OWNER OBJECT_NAME
134 SYS ORA$BASE
143 SYS DUAL
144 PUBLIC DUAL
441 PUBLIC MAP_OBJECT
The user does not need to know that the data is from json/rest or anything. To them it is just data they can work with. Pretty neat.
In the next post we’ll take a look at query-parameters. It is a complex area and we will just scratch the surface. But we can use it for a lot of things even with our simple setup of a rest enabled view.
Lets talk about ORDS IV

This post is part of a series that starts with this post.
Having seen REST-calls from the database to get the raw JSON-response it is time to look at how it can be transformed into separate columns.
This is the SQL we use to get data split up.
select object_id
, owner
, object_name
from (select apex_web_service.make_rest_request
(
p_url => 'https://.../ords/rest_demo_schema/vw_rest_svc/'
, p_http_method => 'GET'
) response
from dual) t
cross join json_table (t.response, '$.items[*]'
columns ( object_id number path '$.object_id'
, owner varchar2 path '$.owner'
, object_name varchar2 path '$.object_name')) j
;OBJECT_ID OWNER OBJECT_NAME
--------- ------ -----------------------
134 SYS ORA$BASE
143 SYS DUAL
144 PUBLIC DUAL
441 PUBLIC MAP_OBJECT
543 SYS SYSTEM_PRIVILEGE_MAP
544 SYS I_SYSTEM_PRIVILEGE_MAP
545 PUBLIC SYSTEM_PRIVILEGE_MAP
546 SYS TABLE_PRIVILEGE_MAP
547 SYS I_TABLE_PRIVILEGE_MAP
548 PUBLIC TABLE_PRIVILEGE_MAP
549 SYS USER_PRIVILEGE_MAP
550 SYS I_USER_PRIVILEGE_MAP
551 PUBLIC USER_PRIVILEGE_MAP
552 SYS STMT_AUDIT_OPTION_MAP
553 SYS I_STMT_AUDIT_OPTION_MAP
554 PUBLIC STMT_AUDIT_OPTION_MAP
705 SYS FINALHIST$
1401 SYS DM$EXPIMP_ID_SEQ
1417 SYS MODELGTTRAW$
1716 SYS AV_DUAL
1790 SYS STANDARD
1792 SYS DBMS_STANDARD
1793 PUBLIC DBMS_STANDARD
1794 SYS PLITBLM
1795 PUBLIC PLITBLM
That looks just like the output from an ordinary table. So we have wrapped it up on one side into a REST formatted response and on the receiving end we unpack it into columns again. Pretty neat.
But we only got 25 rows. We’ll get back to why that is. Let us address the different parts in the SQL to understand what goes on here.
Line 4-9 are similar to what we have seen before. It’s an inline view selecting the data from a REST-endpoint. It gives the json that is returned the alias “response” and the inline view an alias of “t” so it can be referenced later.
Line 10-13 is where the magic happens. The cross join is the effect of a join with now where clauses. Each row from the inline view (there will be just one) is joined with the json_table function. In it we first define what json we want to use as input, t.response is what the online view returned. $.items[*] references all rows in the items array. $ means the root of the json, items is the name of the array, brackets are how individual rows in an array are addressed and * say that we want all the rows. The columns-section picks out columns from the json in each entry in the array. The structure is column name we want, datatype, data element in the json-element (each row in the json-array).
Line 1-3 is noting we have not seen before. You can have * there but you get more then. The inline view returns a “column” t.response that has the raw json. When you have converted that into separate columns you will usually not want that returned anymore so you need to name the columns you do want.
That completes this post where we looked at how to go from returned JSON to get the data as the columns they were in the source. In the next post we’ll take a look at paging and how to get all rows returned to a SQL or via a view.
Let’s talk about ORDS III

This post is part of a series that starts with this post.
Now that we have seen various ways to get data and validate the REST-service working we can move on to implement access from within an Oracle database. I find validating outside the database as the first step to be very valuable. If you have one database that has the rest enabled view, the rest service and then a view in another database reading from that view setup in one go and then it does not work right – there are so many moving parts and som much abstraction that it makes troubleshooting very hard.
Once you can get it to work in cURL, it is usually straightforward to access the same endpoint from within a database.
First we need a user that can make the call to the rest service.
create user rest_demo_caller identified by REST_1234_caller
default tablespace data
temporary tablespace temp;
grant create session to rest_demo_caller;
grant create view to rest_demo_caller;
grant create procedure to rest_demo_caller;Now we can log in as rest_demo_caller and test the rest service. Note that the user having the rest enabled view has a separate name from this user that will invoke it. Typically you’d access a rest-service from one database that accesses another. But it is setup here to allow testing it using just one database.
set serveroutput on
declare
payload clob;
begin
payload := apex_web_service.make_rest_request
(
p_url => 'https://.../ords/rest_demo_schema/vw_rest_svc/'
, p_http_method => 'GET'
);
dbms_output.put_line(payload);
end;
/The result will be identical to that we got from the cURL-call. Just returned in your SQL-tool of choice. I’m using apex_web_service as it simplifies things, we’ll not build an APEX-app here were just using some of its neat infrastructure packages.
If you get an error referring to ACL or access control then you have not granted the database access to make a call to the ORDS-server. This will not happen in an autonomous database, but if you run roll-your-own it may happen. Then modify the following according to your environment and run in the database you want to make the REST-call from.
declare
l_principal varchar2(20) := 'APEX_210200';
begin
dbms_network_acl_admin.create_acl (
acl => 'ords_acl.xml',
description => 'My ORDS-server',
principal => l_principal,
is_grant => true,
privilege => 'connect',
start_date => systimestamp,
end_date => null);
dbms_network_acl_admin.assign_acl (
acl => 'ords_acl.xml',
host => '<The name of you ordsserver goes here',
lower_port => 80,
upper_port => 80);
commit;
end;
/Modify it so it references your APEX-version. If you have not installed it you’ll have to look at alternative ways to make the rest-call. Then the name of your ORDS-server is what you enter in the host-parameter. Just the host, no prefixing hit http or adding patch to the end. Only the name of the server.
Back to accessing the service from the database. So we have seen that we can get the JSON-response with PL/SQL. Let’s now do the same with SQL.
select apex_web_service.make_rest_request
(
p_url => 'https://.../ords/rest_demo_schema/vw_rest_svc/'
, p_http_method => 'GET'
)
from dual;
/Again we get the identical output only now returned as a query result.
We could of course wrap this into a view and have it returned. But it is still just a raw JSON and we would of course want to get the data split up into the rows it is fetching from the rest-enabled view. The next post will be spent on looking a bit at how to get from raw JSON to get the data represented as separate columns.
Let’s talk about ORDS II

This post is part of a series that starts with this post.
Now that we have a restenabled view and we can get data from ut with a basic cURL call, let’s look at more ways to make that call and view the response.
But before those calls, lets look at what data we actually get from the REST-call. If we format the output from the cURL-call it looks something like this.
{"items":[......]
,"hasMore":true
,"limit":25
,"offset":0
,"count":25
,"links":
[{"rel":"self". ,"href":"https://.../ords/rest_demo_schema/vw_rest_svc/"}
,{"rel":"describedby","href":"https://.../ords/rest_demo_schema/metadata-catalog/vw_rest_svc/"}
,{"rel":"first". ,"href":"https://.../ords/rest_demo_schema/vw_rest_svc/"}
,{"rel":"next". ,"href":"https://.../ords/rest_demo_schema/vw_rest_svc/?offset=25"}
]
}
Items is where the arrays of rows returned is kept. I cut out all of that out for brevity. hasMore shows if I can read more data from the service. Limit how much data was requested, offset if data was skipped over before reading and count how many was actually returned. Offset may need a bit more explanation. IF you make a request and then you ask for the next set of 25, then offset will be 25 top show that the requested data starts at row 26. We’ll see that in action later.
Links are misc links to the data. Without hyperlinks in a response, the API is not REST. That is not me saying that, it is how REST is defined.
if the engine of application state (and hence the API) is not being driven by hypertext, then it cannot be RESTful and cannot be a REST API. Period.
Roy T. FieldingWho is he and why does he has a say in what is REST you may ask. He is the primary architect of the Hypertext Transfer Protocol (HTTP/1.1), coauthor of the Internet standards for HTTP and Uniform Resource Identifiers (URI), and a founder of several open source software projects (including the Apache HTTP Server Project that produces the software running most Web servers). On top of that he write the distention that established REST. This part is often referred to as HATEOAS. Further reading about that is just a google-search away.
Back to this from that academic tangent. The links will give you a link to the data returned here, next page, metadata about the service, next set of rows, the first set of rows. If you follow the next, link the result will also have a link for previous set of rows.
With the look at what the response contains out of the way, let’s look at a few more ways to access it.
Let’s begin with letting python format the output for us.
curl https://.../ords/rest_demo_schema/vw_rest_svc/| python3 -m json.toolThat makes the response much more readable, but of course takes up much more space hight-wise. Still, to read and understand it you need something other than the raw response.
Now let’s take the same URL and put it into a web-browser.
If your web browser is set up to format json you will get a response similar to the python one. The links are even active links. Click on next and you get to see the next set of 25 rows. For this tow work you may need an extension in you web-browser. I have JSON Formatter for Chrome. Search for it for your web browser and you will get several to chose from.
In the next post we will take what we did in this and set up in the database to achieve the same with SQL and PL/SQL.
Let’s talk about ORDS I

I recently started looking into a problem at work with getting security added to our setup with views making REST-calls to work as if they were served with a database link. In that work I started from scratch adding one piece at a time to make sure I could troubleshoot it. In doing so I realised that we often talk about the amazing magic of ORDS, but how does one break it down to understand and troubleshoot the smoke and mirrors. What I needed to break down the security setup ended up being what I needed to show my colleagues about what makes ORDS work. It also lends itself to a step by step series on blog-form.
For the blog I’ll convert the on-prem demo to use OCI as everyone can have a free database and ORDS setup there with just a couple of clicks. Installing and getting ORDS working is easy, but not having to do it is easier.
I’m using my free Autonomous Database for the examples. You can do that same with other OCI DB services or on-prem / VM /Docker but you may need to make some adjustments here and there.
You will need to get your base endpoint for the tests.
- On cloud.oracle.com, navigate to your Autonomous database.
- Open Database Actions.
- Click on the hamburger menu and click on RESTful services and SODA under related services.
- Copy and save somewhere the URL that pops up. The one I get looks like “https://ioxxxxxxxxxxxss-evilatp.adb.eu-frankfurt-1.oraclecloudapps.com/ords/”
No, that is not really the name of my tenacy, but close enough. You can verify that it works by issuing this cURL-command.
curl -v https://ioxxxxxxxxxxxss-evilatp.adb.eu-frankfurt-1.oraclecloudapps.com/ords/You’d of course paste the URL you got there instead of my doctored one. It should return quite a bit of text and among other things some lines looking like these towards the end.
< Set-Cookie: ORA_WWV_USER_9274378038389796=ORA_WWV-YbsoJGtYZdGRRlWv-eFSHkQB; path=/ords/; samesite=none; secure; HttpOnly < Set-Cookie: ORA_WWV_RAC_INSTANCE=2; path=/ords/; samesite=none; secure; HttpOnly < Location: https://ioxxxxxxxxxxxss-evilatp.adb.eu-frankfurt-1.oraclecloudapps.com/ords/f?p=4550:1:102000128053637:::::
If you get those cookies and a location looking much like APEX it worked and we can move on with ORDS and REST.
Now let’s set up the base part of getting data from a view in the database via REST. Begin with setting up the user logged in with a privileged user.
create user rest_demo identified by Demo_Rest_1234
default tablespace data
temporary tablespace temp
quota unlimited on data;
grant create session to rest_demo;
grant create procedure to rest_demo;
grant create view to rest_demo;
begin
ords.enable_schema( p_enabled => true
, p_schema => 'REST_DEMO'
, p_url_mapping_type => 'BASE_PATH'
, p_url_mapping_pattern => 'rest_demo_schema'
, p_auto_rest_auth => false);
commit;
end;With that we have a user rest_demo that has access to create procedures and views and the schema is enabled for REST-access.
Now, log in with the user REST_DEMO and create a rest-enabled view.
create view vw_rest as
select object_id
, owner
, object_name
from all_objects;
begin
ords.enable_object(p_enabled => true,
p_schema => 'REST_DEMO',
p_object => 'VW_REST',
p_object_type => 'VIEW',
p_object_alias => 'vw_rest_svc',
p_auto_rest_auth => false);
commit;
end;We have now set up a view that we can access with rest. To wrap up this blog post, let’s just try it by adding to the cURL-command we used before.
curl https://.../ords/rest_demo_schema/vw_rest_svc/{"items":[{"object_id":134,"owner":"SYS","object_name":"ORA$BASE"},
<... snip ...>
{"object_id":1795,"owner":"PUBLIC","object_name":"PLITBLM"}]
,"hasMore":true,"limit":25,"offset":0,"count":25
,"links":[< ... snip ... >]}
That is it, we have a rest service we can call from any environment that can issue a REST-call to get to our data. Pretty impressive to get REST with just a few lines of DDL. The cURL-call has rest_demo_schema and vw_rest_svc to identify schema and view. It is not the name of either but rather aliases to not expose the real names in the database. You can see in the commands above where we gave them alternative names.
That is it for this post. In the next post we’ll look at more ways to make the same rest call and to see the response in a more readable format.
Using package variables in SQL
I often want to use the constants defined in packages also in my SQL. It has in the past never worked and it for the most part still does not.
If I have a a package like this to simplify my code for what department it is I’m looking at.
create package dept_info as
c_accounting constant scott.dept.dname%type := 10;
c_research constant scott.dept.dname%type := 20;
c_sales constant scott.dept.dname%type := 30;
c_operations constant scott.dept.dname%type := 40;
end dept_info;This now allows using dept_info.c_accounting in PL/SQL instead of just hardcoding 10 and having to remember what department 10 is. This is how we usually use PL/SQL and especially with Oracles packages where they often provide constants for ease-of-use.
However if I now try to use it in a SQL, it will not work.
select *
from scott.emp
where deptno = dept_info.c_accounting;
ORA-06553: PLS-221: 'C_ACCOUNTING' is not a procedure or is undefinedInstead of that descriptive reference to the accounting department I have to resort to this.
select *
from scott.emp
where deptno = 10;Then the other day I realised that a feature that is way underused and typically used for allowing declaring programmatic logic in SQL can be used to get access to the constant in the SQL-statement. The with construct can nowadays define a function. That function can return a constant from a package.
with
function c_accounting return number is
begin
return dept_info.c_accounting;
end;
select *
from scott.emp
where deptno = c_accounting
/Pretty nifty, eh? Notice that such SQL cannot be terminated with semicolon as semicolon is used to delimit statements in the PL/SQL so you have to terminate the SQL with a slash in SQL*Plus or SQLcl. Livesql on the other hand parses it just fine if it is terminated with a semicolon.
This is a feature I’m sure will soon be in many SQLs I write.
Change the compatability mode in APEX
I ran across a funny thing today in an application I built 10 yesrs ago but that I have not been involved in maintaining since then. The application is gettings som much needed UI upgrades, like getting out of the dark ages and using universal theme.
During that work there were a set of things that didn’t work, components could nbot be found and some unexpected things happened. Unexpected compared to the behavior that had been experienced while doing a mock app in the private environment in the VM.
It turns out the application still has the compatibility mode set to 4.1. Yes, no wonder it was behaving different than when one has 22.x.
This is set during upgrade if upgrading from a version to another where the new has a change in behavior. You’ll want to look into what the change behavior is and make sure your application works well with it so it is on the latest version.
You find this setting in:
Application Properties -> Definition -> Properties -> Compatibility Mode
Oracle has a running lit of the changed behavior version by version in the documentation. That is great so one does not have to find the docs for each version that has changed behavior to find it. It is in one convenient place.
It goes through the changes for each version where the behavior of the APEX engine changed, starting with 4.1 all the way up to the current version. Very convenient to be able to read up on them and see what one should expect and what to check after changing this setting.
As evidenced by this setting in this application having been forgotten it is worth validating that applications you have upgraded has this set to the value you expect. For me I’d expect the latest unless the work to verify that it works as intended has not been completed.
You ought to have oracledb in your tool chest
No I’m not talking about the Oracle Database. It is extremely unlikely that you found your way here if it isn’t already to some extent your specialisation. If you made it here and have no idea what this is about, drop a comment and let me know your path here if that were to be the case.
No, this is about Python. Even more it is about the OracleDB module for python. That capitalisation is mine, the official way to write it is Python-oracledb. Either way it is Oracle’s implementation of the Python Database API 2.0 specification.
I know what some of you may be thinking. Why would I need that, I’ve got my old trusted cx_Oracle driver. Yes you do and you have nothing to fear, Python-oracledb is the new name for it. You’ll feel right at home.
Let’s start with recognising what a beautiful API. To me this is an API that is equally natural to use from Python and database perspectives. I think it is not just due to Oracle’s efforts but also for the general API specification that it follows. I often find the interface between language and SQL more natural in Python than even in PL/SQL. Yes, that is probably close to an offensive statement for some. But try it before you diss it.
Speaking of Python, if you too work with developers that mainly write code in Java, you will want to be able to write simple stubbs of code to access the database and achieve the things you want them to implement to help you do your job. Most of the time it is enough with some cookie cutter code and just add what you need.
I use Python the same way but for slightly different reasons. I use it to show myself a concept of the work one has to do when accessing the database from outside the database. It also includes things that makes many things easy to test out that for me is beyond cumbersome to set up in Java. In addition Python is a language you want to have in your toool chest anyway as it is the preferred language for data these days.
Let’s rig a small test. Begin with installing the module.
python -m pip install oracledb --upgrade --user
Test getting a connection with som boiler plats code.
import oracledb
with oracledb.connect(user='<USER>', password='<PASSWORD>', dsn='CONN STRING>') as connection:
with connection.cursor() as cursor:
sql = """select sysdate from dual"""
for r in cursor.execute(sql):
print(r)As one would expect it just prints the sysdate. However this blog is not about examples for coding with oracledb, rather I think it is worthwhile to just finish up with highlighting som of the features it has to show the kind of things you can try out with just a few more liens of code.
The plain way of using it uses the thin driver which mimics how most application servers connect. If you want to you can set up for using thick mode also. It is required for som advanced usage scenarios.
Some of the features I think are of particular interest:
- Advanced Queueing including receiving database notifications.
- Support for EBR
- Supporting setting context when creating a connection to allow for better instrumentation in the database.
- Support for E2E monitoring and tracing
- Database Resident Connection Pooling
- ref cursors
- Array-operations
- JSON
And the list goes on.
One final thing I find very interesting. It has an API to set up a connection pool so you can use it to model use cases for how a connection pool would behave. It also allows you to do things like build a REST-server with it’s own connection pool to service parallell requests to your REST-server.
Take it out for a spin, I’m sure you’ll enjoy it.
ORDS REST services work but APEX does not
This is an odd situation, most people are probably struggling more with getting REST to work than to get installed APEX to come up with the login.
I encountered an odd situation recently where REST worked, SQL Developer Web worked but APEX did not. Many attempts to install and uninstall ORDS and we were still at the same situation. The error message we got was along the lines of “connection pool is a template pool”.
Eventually I noticed that the setting for proxied in the pool was disabled. How odd, we did request it in our command. It turns out this happens if you install ORDS in a CDB but there is no APEX in the PDB$SEED. There is even a pretty explicit comment about it high up in the output from the install.
So we have a situation where we installed ORDS in CDB with pluggable mapping of the PDBS. APEX is just installed in the PDBS. Not in PDB$SEED and not in the CDB. So how does one fix it? It turns out just changing the setting back to proxied is enough. You can do it with the ORDS config command.
You may see some Java stacktraces in your log. For us they only occured in a pretty specific case. Either way it does not hurt anything other than that the user gets en error for the slightly invalid request they made.
I may get around to write a few words about our observations on that too.
When TNS does not work in ORDS
This is probably a short lived blog post. If you are using ORDS 22.4 (the current version as of this writing) you may encounter problems with the TNS-support for setting up connections.
I believe they manifest when your TNS-entry has multiple hosts in them as you would if you have a setup with one or more standby databases. In such cases it looks something like this.
SVC =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = host1)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = host2)(PORT = 1521))
)
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = svc)
)
)I believe this is due to the parsing of the file not taking this kind of setup into account. When this happens one can only opt for the basic setup. That only allows for a setup to one specific host. Consider a typical pool.xml with basic connection set up.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>Saved on Mon Mar 06 08:58:12 UTC 2023</comment>
<entry key="db.connectionType">basic</entry>
<entry key="db.hostname">host1</entry>
<entry key="db.port">1521</entry>
<entry key="db.serviceNameSuffix"></entry>
<entry key="db.servicename">svc</entry>
<entry key="db.username">ORDS_PUBLIC_USER</entry>
<entry key="feature.sdw">true</entry>
<entry key="plsql.gateway.mode">proxied</entry>
<entry key="restEnabledSql.active">true</entry>
<entry key="security.requestValidationFunction">ords_util.authorize_plsql_gateway</entry>
</properties>Line 6 and 7 are the critical ones. They show where to find the listener. Should this database be switched over to host2, this will no longer work. Every attempt to connect will now fail.
To manage this you rename pool.xml to h1 (for host1) or some such. Then you make a copy of it to say h2. Now you can create a link with the name pool.xml that points to h1. Now it works when host1 is where your primary database is running and if it is switched to host 2 you just update the link to point to h2. that is all you need to for ORDS to go to host2 for it’s connections.
A script can be set up that uses the H1 and H2 files to find where they look for their databases and then use that to log in and check where your database is located and automatically switch the link if the database has switched. I do that for a set of CDBs each with their own connection pool so if a switch occurs then ORDS gets an updated link shortly thereafter and there is no manual intervention needed.
You will of course rather use proper TNS for it, so do verify that you have this issue before you implement this workaround.
Should you need to do this and want to automate it, get in touch with me and I’ll share the script with you. That is if I have not gotten around to blog about it, even though it’s not going to be needed much longer (I hope), there are som interesting things that can be done with parsing the pool.xml from a script.
Enable Enterprise Manager Express
There are many blogs about the product and so on. I want to recommend that you enable and give your developers access to it. Setting them up and getting them to scale the mountain of complexity that is the normal Enterprise Manager is probably not what you want to do.
However, EM Express is a slimed down version focusing pretty much on just what a developer ought to care about, seeing the processes in the database and data about how they perform. Maybe in production, but probably more useful for most in development environments as that is where they spend their days.
Enabling it is easy enough. If you have Oracle DB XE running it is enabled by default so “http://localhost:5500/em” should bring up the login. For other editions you’d just enable it in the database.
--Check if it is running with
select dbms_xdb_config.gethttpsport from dual;If the select returns a number like 5500, it is already open and you should be able to point your browser to it. “http://<hostname>:<port>/em”
--If it returns zero, then activate by
exec dbms_xdb_config.set httpsport(5500) Now if you are running with multitenant you can use the same port for CDB and all PDBs. Assuming you opened to port in CDB$ROOT, you can set it to also (at least from version 19) allow access to PDBs by allowed accounts.
exec dbms_xdb_config.setglobalportenabled(TRUE);Now you can enter the PDB-name in the container field on the login to get Enterprise Manager Express focused on a specific PDB.
In addition to this, you need an account hat has access to view it. Any DBA-account will do. However, not every user in the databas has access to one. So you can give users EM_EXPRESS_BASIC or EM_EXPRESS_ALL roles to allow access. _BASIC is pure read only access while _ALL gives full access to all features of EM Express. Both these roles also give SELECT_CATALOG_ROLE.
Do note that some features in EM Express – som would say most – requires additional licenses. So configure what parts of enterprise manager you have licensed in your databases. It is done via the init parameter control_management_pack_access.
Add hint to SQL you cannot modify
The last post showed how to lock the plan for a SQL that switched plan every now and then. Another common issue one can encounter is that of a SQL that uses a suboptimal plan and for which you’d want it to use a different plan. The way to instruct the optimiser to use a different plan is to use a hint to cause it to change how it accesses the table.
But often the SQL is in application code you may not be able to change right away or even in a packaged application where you have no access to the source code. For those situations it would be convenient to just inject a hint into the SQLand have it take effect anytime the original SQL is executed.
We’ll use SQL Plan Management (SPM) to achieve that too. We’ll first load the plan we don’t want to use and set it to no enabled and then we’ll add a hinted SQL as enabled that we want to use.
We start with the same setup as last time. That setup works to prove this case also
For this to work there is just one parameter we need to have set. optimizer_use_sql_plan_baselines needs to be set to true. It has been the default since SPM was introduced in version 11.
You can verify the setting in your database with:
sho parameter optimizer_use_sql_plan_baselinesLet’s set up a table and add some data + an index.
create table a ( id number(10) not null
, text varchar2(200) not null);
declare
type ti is table of pls_integer index by pls_integer;
ai ti := ti();
type tv is table of varchar2(200) index by pls_integer;
av tv := tv();
begin
for i in 1..10000 loop
ai(i) := i;
av(i) := dbms_random.string(opt=>'p', len => 200);
end loop;
forall i in 1..10000
insert into a (id, text) values (ai(i), av(i));
commit;
end;
/
create index b on a (id);With 10000 rows we’ll have enough for our test case. With this setup we’re bound to get an index lookup.
var a number;
exec :a := trunc(dbms_random.value(1,10000));
select * from a where id = :a;SQL_ID 846t2s6wt24bw, child number 0 Plan hash value: 1556772684 ------------------------------------------------------------- | Id | Operation | Name | E-Rows | ------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 1 | TABLE ACCESS BY INDEX ROWID BATCHED| A | 1 | |* 2 | INDEX RANGE SCAN | B | 1 | -------------------------------------------------------------
For this case we assume that what we want is to not use the index. We want a full scan. All we want to prove is to add a hint and make it take effect. If it actually is better is not relevant.
So far so good. Now let’s capture this plan for SPM. For this we need SQL_ID. Turn autotrace on (set auto trace on) in SQLcl and you get it directly after the SQL.
This time we combine the loading of the plan with the setting of it to not be enabled.
var cnt number;
exec :cnt := dbms_spm.load_plans_from_cursor_cache( sql_id => '846t2s6wt24bw' -
, enabled => 'No')We can now see the plan we have captured.
select sql_handle, plan_name, enabled from dba_sql_plan_baselines;SQL_HANDLE PLAN_NAME ENABLED SQL_4dba70cebd906150 SQL_PLAN_4vfmhtuyt0sah760b7ebb NO
Our next step is to execute a hinted version of the SQL and then load that as an enabled SQL.
First execute the SQL with a hint.
exec :a := trunc(dbms_random.value(1,10000));
select /*+ full(a) */ * from a where id = :a;SQL_ID fkztgs54b40h3, child number 0 Plan hash value: 2248738933 ------------------------------------------- | Id | Operation | Name | E-Rows | ------------------------------------------- | 0 | SELECT STATEMENT | | | |* 1 | TABLE ACCESS FULL| A | 1 | -------------------------------------------
That is it, we have the SQL running with a full scan. Exactly what we wanted and exactly how that hint should perform. But now we want the original SQL to use this plan.
Let’s load the sql with the new sql_id and the plan_hash_value it got to the sql_handle we have from the original loaded SQL and set it to be enabled. Enabled has a default of YES, so that part is just to be more declarative in our intent.
exec :cnt := dbms_spm.load_plans_from_cursor_cache -
( sql_id => 'fkztgs54b40h3' -
, plan_hash_value => 2248738933 -
, sql_handle => 'SQL_4dba70cebd906150' -
, enabled => 'YES');Net’s first check that we got one more plan loaded to our SQL Handle.
select sql_handle, plan_name, enabled from dba_sql_plan_baselines;SQL_HANDLE PLAN_NAME ENABLED _______________________ _________________________________ __________ SQL_4dba70cebd906150 SQL_PLAN_4vfmhtuyt0sah60236d92 YES SQL_4dba70cebd906150 SQL_PLAN_4vfmhtuyt0sah760b7ebb NO
Great, we added another plan and it is enabled. Time to take it out for a spin. We run the original version of the SQL – the one without the hint – and if it works we’ll see it use a full table scan.
exec :a := trunc(dbms_random.value(1,10000));
select * from a where id = :a;------------------------------------------- | Id | Operation | Name | E-Rows | ------------------------------------------- | 0 | SELECT STATEMENT | | | |* 1 | TABLE ACCESS FULL| A | 1 | -------------------------------------------
Fantastic, we have managed to change the plan used for a SQL that we’re unable to modify the SQL for. With this we can in a matter of minutes adjust then plan used for a SQL Not that the auto trace now shows this happening.
- SQL plan baseline SQL_PLAN_4vfmhtuyt0sah60236d92 used for this statement
This is of course usable for any kind of SQL. I’m just using a very simple one to show the mechanics and not be bogged down in the intricacies of a complex SQLs many possible execution plans.
We’ve still just scratched the surface of what is possible with SPM. But when it comes to manually controlling SQL plans the last post and this will probably cover at least 90% of the issues you need to deal with.
All we have left is to remove the plans so there are no remnants after the test of SPM.
exec :cnt := dbms_spm.drop_sql_plan_baseline -
( sql_handle => 'SQL_4dba70cebd906150');
select sql_handle, plan_name, enabled from dba_sql_plan_baselines;Since both plans had the same handle, both were dropped by only providing the handle in the drop. The SQL proves it by not returning any rows.
This is a technique that often is very useful when you have SQL that uses a plan that is not performing as good as the alternative. If the SQL in question cannot be modifies due to release windows or because it is not in code your control, being able to adjust the plan used is very efficient.
Lock the plan for a SQL
A SQL that sometimes just uses a plan you prefer it to not use is fairly common. There are always reasons for unstable plans, but more important than knowing the reason is often to make it stick to a certain plan.
This has historically been done with a lots of ways from changing the SQL, adding hints, adding incorrect stats to influence the optimizer, using any of the techniques that came before SQL Plan Management (SPM). All of these has their issues. The first two required code changes and if it was in a product you cannot modify you could not use them. Using the previous techniques for locking a plan had their issues, hence they were superseded with new ones.
SPM comes with a whole set of APIs one can use to achieve what one want. It has support for full automatic mode to full manual mode. In this blog post I’ll look at just the manual way to set a SQL to use a specific plan.
For this to work there is just one parameter we need to have set. optimizer_use_sql_plan_baselines needs to be set to true. It has been the default since SPM was introduced in version 11.
You can verify the setting in your database with:
sho parameter optimizer_use_sql_plan_baselinesLet’s set up a table and som data.
create table a ( id number(10) not null
, text varchar2(200) not null);
declare
type ti is table of pls_integer index by pls_integer;
ai ti := ti();
type tv is table of varchar2(200) index by pls_integer;
av tv := tv();
begin
for i in 1..10000 loop
ai(i) := i;
av(i) := dbms_random.string(opt=>'p', len => 200);
end loop;
forall i in 1..10000
insert into a (id, text) values (ai(i), av(i));
commit;
end;
/With 10000 rows we’ll have enough for our test case. With this setup we’re bound to get a full table scan.
var a number;
exec :a := trunc(dbms_random.value(1,10000));
select * from a where id = :a;------------------------------------------- | Id | Operation | Name | E-Rows | ------------------------------------------- | 0 | SELECT STATEMENT | | | |* 1 | TABLE ACCESS FULL| A | 83 | -------------------------------------------
So far so good. Now let’s capture this plan for SPM. For this we need SQL_ID. Turn autotrace on (set auto trace on) in SQLcl and you get it directly after the SQL. Or use “set auto trace on sql_id” to get the sql_id from every SQL you run in SQLcl. Or pull it by searching for the SQL in v$sql or for your session in v$session. Or any other way you prefer.
var cnt number;
exec :cnt := dbms_spm.load_plans_from_cursor_cache(sql_id => '846t2s6wt24bw');We can now see the plan we have captured.
select sql_handle, plan_name, enabled from dba_sql_plan_baselines;SQL_HANDLE PLAN_NAME ENABLED SQL_4dba70cebd906150 SQL_PLAN_4vfmhtuyt0sah60236d92 YES
Now create an index so we can get another plan for the same SQL to let us pick which we want to use.
create index b on a (id);Now let’s run the SQL again and see that we get a plan using the index.
exec :a := trunc(dbms_random.value(1,10000));
select * from a where id = :a;------------------------------------------- | Id | Operation | Name | E-Rows | ------------------------------------------- | 0 | SELECT STATEMENT | | | |* 1 | TABLE ACCESS FULL| A | 1 | -------------------------------------------
But wait… Full table scan? Didn’t we just create an index? How odd! Not at all, we just proved that SPM does work. Remember the plan we captured? It is enabled and is now making this SQL always use a full scan. Let’s disable it and see if we get index access.
But first look at the output from auto trace, assuming you are using SQLcl. It has a hint of this in the notes section.
- SQL plan baseline SQL_PLAN_4vfmhtuyt0sah60236d92 used for this statement
That is the one we want to disable.
exec :cnt := dbms_spm.alter_sql_plan_baseline -
( sql_handle => 'SQL_4dba70cebd906150' -
, plan_name => 'SQL_PLAN_4vfmhtuyt0sah60236d92' -
, attribute_name => 'enabled' -
, attribute_value => 'NO');Now with that disabled we can try the query again.
select * from a where id = :a;------------------------------------------------------------- | Id | Operation | Name | E-Rows | ------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 1 | TABLE ACCESS BY INDEX ROWID BATCHED| A | 1 | |* 2 | INDEX RANGE SCAN | B | 1 | -------------------------------------------------------------
Great, now we get the index to be used as expected and we have a new plan we can capture. Let’s get that plan also.
exec :cnt := dbms_spm.load_plans_from_cursor_cache(sql_id => '846t2s6wt24bw');
select sql_handle, plan_name, enabled from dba_sql_plan_baselines;SQL_HANDLE PLAN_NAME ENABLED _______________________ _________________________________ __________ SQL_4dba70cebd906150 SQL_PLAN_4vfmhtuyt0sah60236d92 NO SQL_4dba70cebd906150 SQL_PLAN_4vfmhtuyt0sah760b7ebb YES
So we have the one with the full scan that we set to not be enabled and the new one that we just captured. A captured plan is by default enabled. Running the select now gets us the same plan using the index we created. There is just one slight difference, it is now using the enabled plan. Autotrace in SQLcl will show this in the notes.
- SQL plan baseline SQL_PLAN_4vfmhtuyt0sah760b7ebb used for this statement
Same thing, it just shows that we have a SQL Plan for the SQL now.
SQLcl is of course not magical, at least not in this sense, the data about the SQL-plan being used is available in Oracle V$-views. If you look up the SQL by sql_id in v$sql, you’ll notice that the column sql_plan_baseline is populated with the name of this SQL-plan.
If we consider the indexed plan undesirable for some reason and the full scan desirable for this particular SQL, we can flip what plan it uses by just changing the SPM-captured plans. To achieve that we need to disable the one that is using the index and enable the one that is doing a full scan. That is, the column enabled needs to be reversed on the plans shown above.
exec :cnt := dbms_spm.alter_sql_plan_baseline -
( sql_handle => 'SQL_4dba70cebd906150' -
, plan_name => 'SQL_PLAN_4vfmhtuyt0sah60236d92' -
, attribute_name => 'enabled' -
, attribute_value => 'YES');
exec :cnt := dbms_spm.alter_sql_plan_baseline -
( sql_handle => 'SQL_4dba70cebd906150' -
, plan_name => 'SQL_PLAN_4vfmhtuyt0sah760b7ebb' -
, attribute_name => 'enabled' -
, attribute_value => 'NO');
select sql_handle, plan_name, enabled from dba_sql_plan_baselines;SQL_HANDLE PLAN_NAME ENABLED _______________________ _________________________________ __________ SQL_4dba70cebd906150 SQL_PLAN_4vfmhtuyt0sah60236d92 YES SQL_4dba70cebd906150 SQL_PLAN_4vfmhtuyt0sah760b7ebb NO
That looks like expected, will we now get the plan we have defined as the one we want. That is we should get a full scan and a note that SQL_PLAN_dtxx1jqu44h7t60236d92 is being used.
exec :a := trunc(dbms_random.value(1,10000));
select * from a where id = :a;------------------------------------------- | Id | Operation | Name | E-Rows | ------------------------------------------- | 0 | SELECT STATEMENT | | | |* 1 | TABLE ACCESS FULL| A | 1 | -------------------------------------------
Exactly what we expected and wanted to achieve. We have successfully gotten a different plan picked than the one the optimiser picks without the SPM-setup we have introduced. The note in the explain plan from auto trace in SQLcl shows that it is using the SQL-plan.
- SQL plan baseline SQL_PLAN_4vfmhtuyt0sah60236d92 used for this statement
There are tons more that can be done with SPM, but this concludes the scope of setting up a manual picked plan we want to be used. All we have left is to remove the plans so there are no remnants after the test of SPM.
exec :cnt := dbms_spm.drop_sql_plan_baseline
( sql_handle => 'SQL_4dba70cebd906150');
select sql_handle, plan_name, enabled from dba_sql_plan_baselines;Since both plans had the same handle, both were dropped by only providing the handle in the drop. The SQL proves it by not returning any rows.
This is a technique that often is very useful when you have SQL that sometimes uses a plan that is not performing as good as the alternative. There is much more to say about SPM, but this technique is in my experience where most people starts their learning of what can be achieved. Have fun with it and do play around with it to get experience with how to grab both good and bad SQL-plans so you can instruct the optimiser about which plan you prefer it to use.
Set operators – Union, intersect and minus
You’ve probably combined two queries with “union”, but have you looked at the different options for how to combine queries? The set operators are more combining result sets than they are combining queries even if we often think about it is combined queries.
Thy need to return the same number of columns of the same datatypes. The lengths of the columns can differ but not the datatypes.
Let’s start with a couple of tables and data so you have something to test with.
create table t1 (ix number, name varchar2(25));
create table t2 (ix number, name varchar2(25));
insert into t1 values(1, 'Charles');
insert into t1 values(2, 'John');
insert into t1 values(3, 'Steve');
insert into t2 values(1, 'Ben');
insert into t2 values(2, 'John');
insert into t2 values(3, 'Ari');Let’s start with the version of a union that I think of as the default even if it has more keywords. “Union all” just concatenates two result sets making it the most basic form of a union.
select ix, name from t1
union all
select ix, name from t2IX NAME 1 Charles 2 John 3 Steve 1 Ben 2 John 3 Ari
As you can see it is just the output from the first query followed by the output of the last. No sorting, no eliminating duplicate rows (#2 is a dup).
The next variation of union is of course doing exactly that, lets remove the extra #2.
select ix, name from t1
union
select ix, name from t2IX NAME 1 Ben 1 Charles 2 John 3 Ari 3 Steve
Now it is sorted left to right and the extra #2 that was identical to the first is removed. The order of the rows is undefined even if the data tends to be sorted left to right.
If we were to do a select on ly on column IX, we’d end up with just three rows as the values in that column is repeating. Both tables has the value 1, 2, and 3.
Those two variants are pretty common in everyones SQL. Let’s look at the next that many people seem to forget about.
select ix, name from t1
minus
select ix, name from t2IX NAME 1 Charles 3 Steve
As you can see it is the rows from the first query where rows that are identical in the second query are removed. This could of course be written with “where not exists” or “where not in”, but when the minus set operator works it is usually easier to read and describes the intent better.
On to the variant that I think few even know exists, intersect is similar to a join. In fact it can be written as one.
select ix, name from t1
intersect
select ix, name from t2IX NAME 2 John
This combines both result sets and keeps only those where there is an identical row in both. It is pretty much the opposite of the minus operator. Minus removed the #2 while intersect returns only #2
It could be written as a join where you join on every column returned in the select. For a small query like the example here it is quick to write the join. But consider a situation with 25 columns, writing a join with 25 columns in the join condition is not that fun to write.
Now let’s look at one way to control the order in which the set operator is evaluated. This query will of course return three rows all with a 1.
select 1 from dual
union all
select 1 from dual
union all
select 1 from dualTo make it a little bit more interesting, let us change a union all to union. Try to figure out the number of rows returned before reading on.
select 1 from dual
union all
select 1 from dual
union
select 1 from dualThe result is 1 row. You may have thought there would be 2, one from the first that is not having duplicates removed and then one for the last two. But that is not how it is done, it does the onion all on the first two and that result is then used with the union to the last so identical rows are removed and thus only one row with a 1 is returned.
Next question. What happens if the query starts with a union and ends with a union all, do you get the same result? No you do not and you’re right I would not have asked if you did. In that case the first two queries has a row removed due to union removing duplicates. That results is then used in a union all with the last query resulting in two rows each containing a 1.
How about controlling the order in which queries are evaluated and set operations performed? Take a look at this, if you have not seen it before then the parenthesis are probably odd looking.
select 1 from dual
union
(
select 1 from dual
union all
select 1 from dual
)Without the parens it is the same query as variant discussed above that began with a union and ended with a union all. Thus with the parens removed it returns two rows – the union of the first two queries are concatenated with the result of the last – but the parens changes the order of evaluation just like in a where-statement. Here the selects in the parenthesis is evaluated. That is first the result of the second and third query is concatenated and that is the combined with the first and duplicates are removed. As a result the whole query returns just one row.
That is it. There is a lot of power in the set operators and you can do much more with them than first meets the eye.
Longs in SQL
Using long datatype is a problem we seldom face with new applications. But some old may still have it if they have not managed to convert to somethings easier to work with. But where I most often encounter it is in Oracles tables. The place that by far most often pops up its ugly head is high_value in *_tab_partitions. Just the other day a colleague was stuck on how to grab a portion of its content in SQL.
“You cannot” was not really the expected answer. My clarification “more work than you will want to do” wasn’t appreciated much more. We agreed that as he was going to use it in PL/SQL anyway, it was enough that it works in PL/SQL.
The issue is this:
select to_char(high_value) from all_tab_partitions;
ERROR at line 1:
ORA-00932: inconsistent datatypes: expected CHAR got LONG
select to_char(high_value) from all_tab_partitions;
ERROR at line 2:
ORA-00932: inconsistent datatypes: expected CHAR got LONGSo a long cannot be converted implicitly or explicitly to varchars. How do you deal with it then? The standard handling of it is to do SQL in PL/SQL and operate on the long there.
begin
for r in (select high_value from all_tab_partitions)
loop
dbms_output.put_line(substr(r.high_value,1));
end loop;
end;
/That does work and you can of course then use it for any kind of PL/SQL magic you want. Like pipelined functions.
If you’re like me, you will think “aha, then I can fix this with a refactoring function”.
with
function with_function(p_hv in long) return number is
begin
return substr(p_hv,1);
end;
select with_function(high_value) from all_tab_partitions
/
ERROR at line 6:
ORA-00997: illegal use of LONG datatypeOK then, how about a function that just returns the varchar?
create function l2vc(lng in long) return varchar2 is
begin
return substr(lng, 1, 10);
end;
/
select l2vc(high_value) from all_tab_partitions;
ERROR at line 1:
ORA-00997: illegal use of LONG datatypeSo SQL does not play nicely with LONG. Can you add more complexity and get it to be somewhat possible. Sure, but for most that is overkill. Just do what you need in PL/SQL.
Since it is possible, why hasn’t Oracle fixed it a long time ago? Oracle’s own tables are probably not fixed due to legacy restrictions on stuff that expects these columns to be long. As for providing means in SQL to support it, it would not help. You are not advised to ever use LONG, making it easier to do so is not helping the situation so do not expect a supported way for SQL to do this. And do not put LONG columns into your application.
The lasting impression #JoelKallmanDay
It feels as if this year the feelings are not too raw anymore to even consider writing about Joel. Can anything new be said that hasn’t been said better by much more important people. Probably not, but their story is not my story.
A day honouring Joel is not just a day his name brings out a flurry of blogs and tweets. It is a day to remember who he is. There is no was about Joel, his life has a lasting impression on anyone he touched.
I was by no means a close friend of Joel. He was of course much more important to me than I was to him. I feel that is probably the case for just about everyone. But he is the essence of “they will soon forget what you did, but they will never forget how you made them feel”. Joel had the ability to make anyone feel like they for a moment were the most important and interesting person around. I don’t even know how anyone would imitate it. I think the thing is that it cannot be imitated, it has to be 100% honest.
I have been at conferences where Joel stands in a room surrounded by Oracle fanboy superstars. The likes of which we all know the names by heart. I’m not a shy person but I shy away from crowds I don’t feel I belong in. So I end up elsewhere in the room talking to someone, having a beer or just thinking about the conference. Joel would while he is busy being the life of the party for some 20+ people see that I passed by and at some point make his way over to chat some and do his best to introduce and make me feel at home with the in-crowd.
Such discussions with Joel made the community come to life for me and while there are rough edges in it, Joel saw none and exhibited none. He was for community to a point I know few who can. People on his level has worked hard to get there and as such want to be seen. Joel was always the center of the attention but always made every attempt to direct the light at the community and the user groups.
The community is what it is because of Joel. I think even Oracle is what it is because of him. Oracles “back to cool” and developer focused initiatives seemed to get more and more traction at the same speed as Joel got the community to see itself as a world wide phenomenon. How things changed can probably be seen in the number of said superstars that has returned to the mother ship over the last few years.
So what is the point with all of this? Who knows. I’m probably just wanting to remember Joel and to wish for a community where light is shone at the audience and not the superstar speakers. Bringing the community together the way Joel did with no thought of who is good enough, if you want to be part of it then you are.
Thinking about Joel being gone and his big smile not waiting for us at the next conference makes me sad. But what he created and how it continues with a community that has very few “mean boys” makes me very happy. People like Joel that makes any community easier to enter and less pain felt for not yet being at par with the best is what makes the APEX community such a rock star community. I have been part of many communities in tech. I’ve been proud to have been in some. But the APEX community is the only one I’m proud of. Not proud of being in it, just proud of what it is and what it stands for.
Grabbing an AWR without access to the database server
Getting an AWR can sometimes be difficult. If you are on an autonomous database you cannot log in to the database server and run your trusty old script for it. Other times you may not have the access and cannot get the DBA to find time to help you with it every time you want to look at one.
Fortunately you can leverage your PL/SQL skills and just get it through any tool you want to use.
The first thing you need is the snap_ids you want to use. Each time data is saved for an AWR it is given a new sequential higher snap_id. So you’ll want to list the ones you have available to generate an AWR from.
select snap_id
, begin_interval_time
, end_interval_time
from dba_hist_snapshot
where dbid = (select dbid from v$database)
and instance_number = (select instance_number from v$instance)
order by snap_id desc;Of course if it is not a recent snap you are looking for you may want to filter it by begin_interval_time.
Now that you have the two snaps that covers the time you are interested in, you’ll want to generate it so you get the output locally on the environment you work on. Note that you need to enable dbms_output in order to get the output from the script.
undefine enter_start_id
undefine enter_end_id
begin
for r in (select output
from table(dbms_workload_repository.awr_report_html
( (select dbid from v$database)
, (select instance_number from v$instance)
, &enter_start_id.
, &enter_end_id.
))) loop
dbms_output.put_line(r.output);
end loop;
end;
/By entering the two snap_ids form the output of the first SQL you will get an AWR in the form of HTML. Just save it to a file and open it in your favourite web-browser to see the AWR.
Disclaimer: The basis for the code used here is taken from Maria Colgan who showed this technique and some other variants. I have modified the code from there to in my mind be easier to use and demonstrate. See her blog to read about other ways to do it, including how to grab the AWR for most recent snaps with SQL Developer.
Create and terminate DB from Visual Code
We saw earlier how easy it is to start and stop autonomous databases from Visual Code. Now we’ll use ODT (Oracle Developer Tools for Visual Studio Code) to create a new, access it and then toss it.
First if you do not have a cloud environment or set up ODT for it, take a look at Oracle Tools Is Great, Start ATP With A Click to get the basic configuration up. Here we’re starting from the point where you already have at least one OCI-environment configured in ODT.
That means that in ODT you have an entry like this, if it is empty then look at the mentioned blogpost for how to configure it,

Open up your OCI connection and right click on any of the three database types – ATP, AWH, JSON – and select “Create New…”. The dialog looks like this.
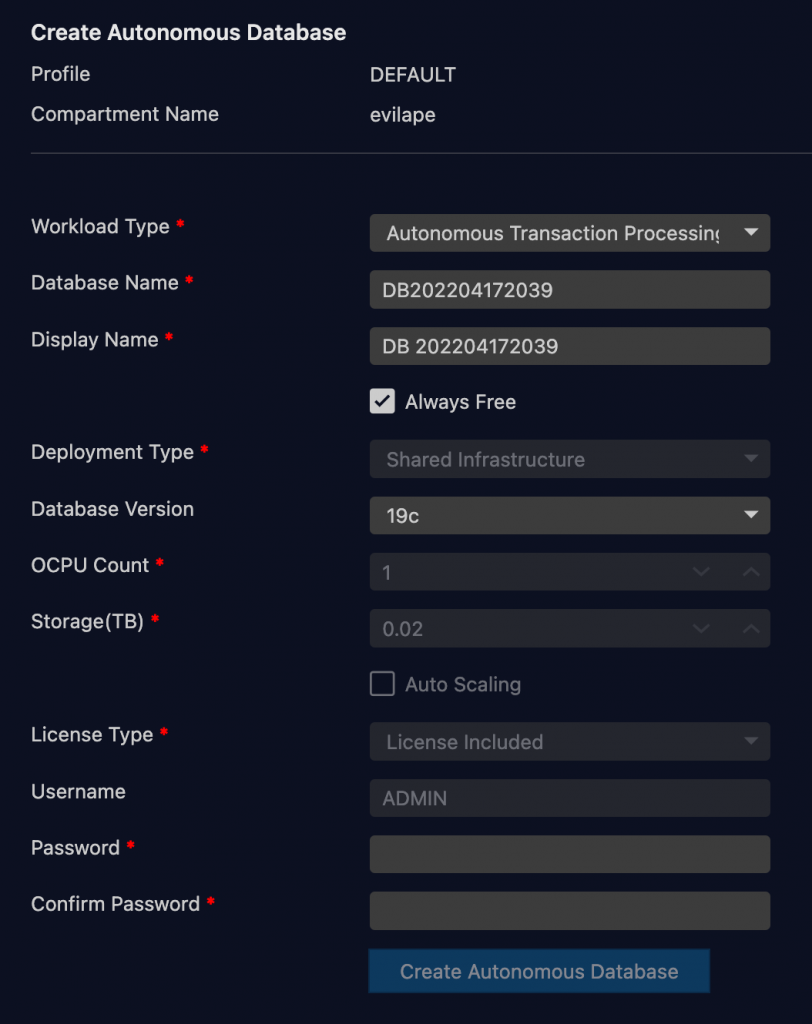
Workload type lets you chose another database type than the one you clicked create new on. Then you can name it something meaningful.
Note that it defaults to “Always Free”, at least for a tenancy created as such. Nice to not end up creating one you pay for by mistake.
Then you can chose version of the database. Right now it is 19c and 21c.
CPU, Storage, auto scaling, and license type cannot be entered for always free databases.
Lastly you enter the password you want for the admin account in the database.
With those things entered you can just click Create.
For the process look in the output for Oracle Developer Tools, you’ll see something like this.
Information:4/17/2022, 8:53:22 PM: Database: blogdb - PROVISIONING Profile: DEFAULT Compartment: evilape Workload Type: Autonomous Transaction Processing Database Name: blogdb Display Name: blogdb Always Free: true Deployment Type: Shared Infrastructure Database Version: 19c OCPU Count: 1 Storage(TB): 1 Auto Scaling: false License Type: License Included Information:4/17/2022, 8:54:27 PM:Database: blogdb - AVAILABLE
As you can see it took all of 63 seconds to bring up a brand new PDB. Fast enough to create it, run some tests and just toss it. Let’s set up a connection to it.
Right click on the new database on the OCI section on the right side in Oracle Developer Tools, and select Create Connection in Database Explorer.
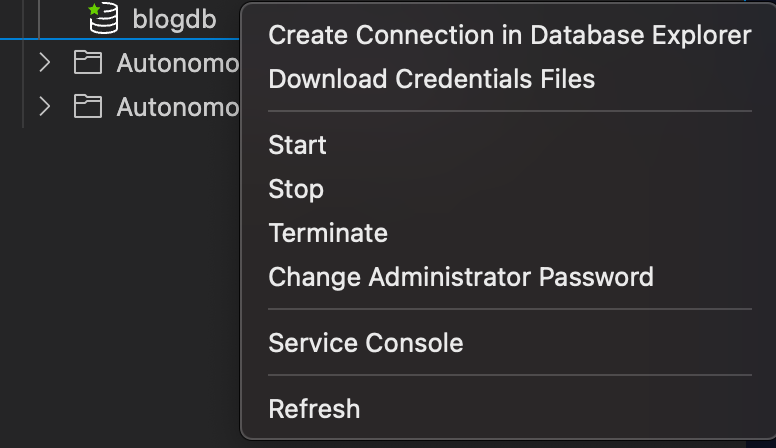
This brings up the create connection with some things set up already, it also allows you to download the needed wallet so you don’t have to worry about that.
The first dialog only let’s you chose where the wallet will be saved and if you want it downloaded (you probably do unless you already have it). In this case, chose a path unless you want the default and allow it to be downloaded and click OK. The wallet is downloaded and unzipped into the folder you selected. Next is a dialog for the rest of the settings.
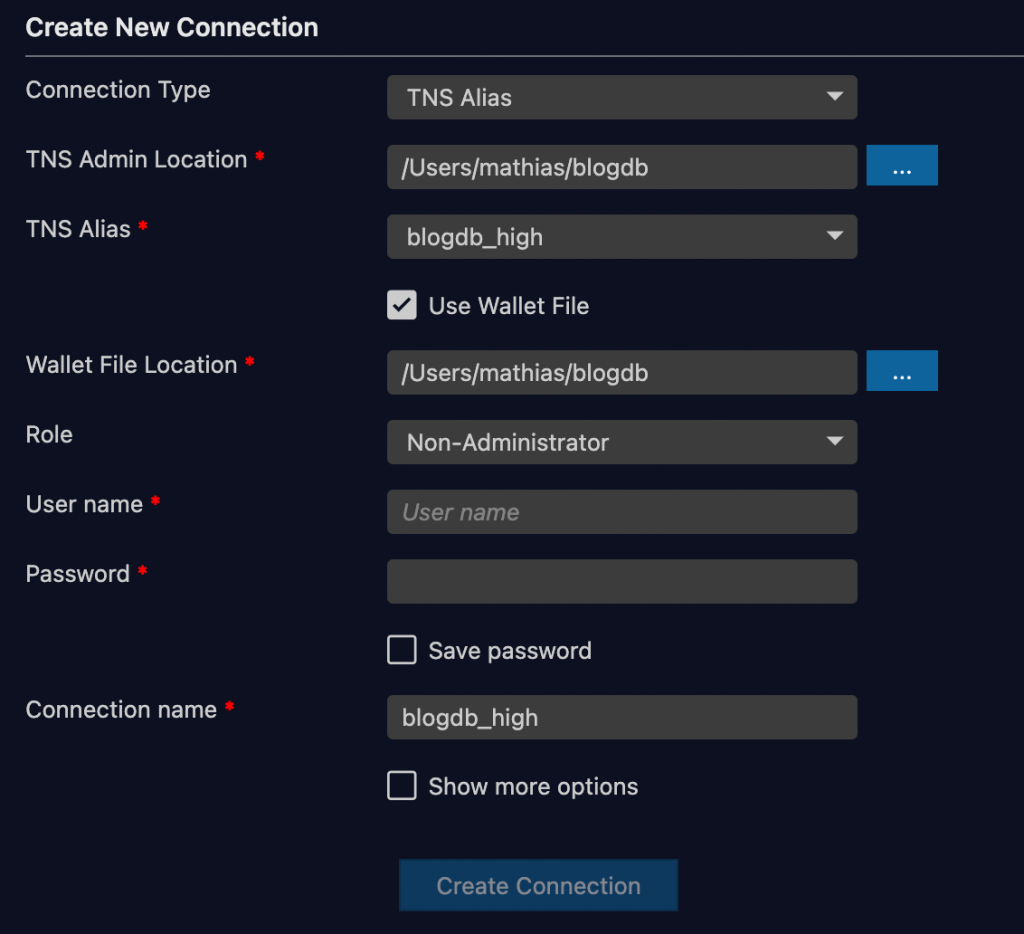
Here you’ll not want to change much. In this case you just have an admin account, so set user name to be admin and password to the one you entered when you created the database. Optionally elect to save the password and then hit create connection.
It is now up in your connections and you can klick on it top open it. Right click on it and select “Open New SQL File”, enter a SQL like “select * from all_objects;” and execute it by right clicking on it and select “Execute SQL”.
It shows that you have access and everything works. You can of course create tables and do whatever your test case requires. Now the only thing left to complete the process is to terminate the database, which means to get rid of it.
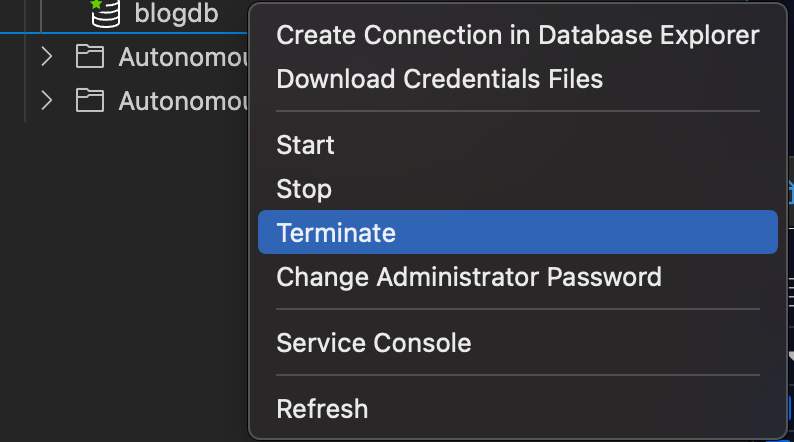
You get a question to make sure you really do want to delete the database. Select yes. It then took almost two minutes for my open PDB to become terminated.
The database is still shown under your databases. Probably as a way to remind you it was terminated. It will dispapear from there in about 12 hours.
To finish cleaning up you may want to remove the connection you created as well as the wallet.
With that you’ve spun through the whole cycle of creating a database doing some testing and getting rid of the database. All from within Visual Code. Pretty neat if you ask me.