
Bobby Durrett's DBA Blog
Gold image for 19.16 install on RHEL 8
On Red Hat 7 Linux VMs we use a zip of a 19c Oracle home with the latest quarterly database release update applied which at the moment in 19.16, the July 19, 2022 version. Our standard deployment script just unzips the gold image zip and then runs the installer silently with a response file. But when I ran the same process on a Red Hat 8 VM I got errors. I found something that said to set this variable to resolve the first error:
export CV_ASSUME_DISTID=’OL7′
And then I got package missing errors which I could ignore about this package:
compat-libcap1-1.10.
But I finally hit an error that I could not get around no matter what I did:
[FATAL] Error in invoking target ‘all_no_orcl’ of makefile ‘/oracle/product/db/19.0.0.0/rdbms/lib/ins_rdbms.mk’.
So, I opened a service request (SR) with Oracle support, and they gave me a series of steps to rebuild my 19.16 gold image zip in a way that would get past this error. There was only once step that I had to add to what they recommended so I want to document that here.
First, they recommended unzipping the base 19.3 install file in my oracle home and then putting in the current opatch. These steps looked like this on my system:
unzip LINUX.X64_193000_db_home.zip -d $ORACLE_HOME
cp p6880880_190000_Linux-x86-64.zip $ORACLE_HOME
cd $ORACLE_HOME
mv OPatch OPatch.orig
unzip p6880880_190000_Linux-x86-64.zip
This just left me with the base 19.3 install and the current opatch in the Oracle home but nothing installed.
Through a bunch of trial and error I found that I needed this step before I went further:
cp /etc/oraInst.loc /oracle/product/oraInventory
Our VMs come with an OEM client pre-installed so there is already an inventory. Maybe that is why I needed this step. I have not had a chance to test this on a clean RHEL 8 VM without an OEM client installed.
Next, I had to run the actual install which required an X server with the DISPLAY variable setup. I had fun getting this to work with MobaXterm and its ssh tunnel feature but once I figured it out it worked great. I ended up setting my DISPLAY variable like this:
export DISPLAY=localhost:0.0
I set the tunnel to listen on port 6000 on my RHEL8 vm and connected it to that same port on the ip for my MobaXterm X server. Maybe that needs a separate post, but other people probably do this all the time.
The install uses this patch:
Patch 34160854: COMBO OF OJVM RU COMPONENT 19.16.0.0.220719 + GI RU 19.16.0.0.220719
I unzipped this to /oracle/db01/install/34160854
Then I ran the install like this:
./runInstaller -applyRU /oracle/db01/install/34160854/34130714
This spit out some text messages about applying the patch but then went into the normal graphical interactive installation steps through X windows. I did a standalone binary install without RAC.
Next, I had to apply the other part of the combo patch:
$ORACLE_HOME/OPatch/opatch apply /oracle/db01/install/34160854/34086870
This ran like a typical opatch apply.
Now that I had followed Oracle’s instructions to install 19.16 in a way that could be made into a gold image that works on RHEL 8 I did the following to make the gold image:
./runInstaller -silent -createGoldImage -destinationLocation /oracle/db01/install
Then I blew away everything in the oracle home and the inventory directory and redid the install from the new gold image like this:
unzip /oracle/db01/install/db_home_2022-09-20_05-53-23PM.zip -d $ORACLE_HOME
$ORACLE_HOME/runInstaller -silent -responseFile $ORACLE_HOME/19cresponsefile.rsp
The response file was the same that we always use for 19c on RHEL 7. Also, I did not need to set CV_ASSUME_DISTID=’OL7′ because the gold image has a recent version of the installer that does not require it. I think the main point of installing from patch 34160854 was to get a patched version of the installer that works with RHEL 8. My old gold image zip was made from the base 19.3 zip with the 19.16 database release update applied. Evidently that did not update the installer to make it support Red Hat 8, so I had to build a new gold image using patch 34160854 as described above.
Anyway, I don’t have a ton of time to go back and clean all this up right now but hopefully this basic dump of information will be helpful to someone. If nothing else, it will remind me!
Bobby
netstat -o shows that (ENABLE=BROKEN) turns on TCP keepalive
In an earlier post I showed a Java program that will login to an Oracle database and wait for 350 seconds. I also talked about how we set the Linux parameter net.ipv4.tcp_keepalive_time to 60 seconds but that I needed to add (ENABLE=BROKEN) to the TNS connect string to enable the keepalive. I found a helpful post that said to use netstat -a -n -o to see connections that are using TCP keepalive. So, I tried my Java program with and without (ENABLE=BROKEN) and ran netstat -a -n -o both ways and it showed that keepalive was only working with (ENABLE=BROKEN).
with (ENABLE=BROKEN)
$ netstat -a -n -o | grep 10.99.94.32
tcp6 0 0 172.99.99.187:44314 10.99.94.32:1523 ESTABLISHED keepalive (27.30/0/0)
$ netstat -a -n -o | grep 10.99.94.32
tcp6 0 0 172.99.99.187:44314 10.99.94.32:1523 ESTABLISHED keepalive (41.47/0/0)
without (ENABLE=BROKEN)
$ netstat -a -n -o | grep 10.99.94.32
tcp6 0 0 172.99.99.187:54884 10.99.94.32:1523 ESTABLISHED off (0.00/0/0)I edited the IP addresses to obscure them and removed spaces to make it fit better, but the important thing is that with (ENABLE=BROKEN) the 60 second keepalive timer is working, but without it the timer is off.
This information might not be that helpful to others if they do not have this kind of timeout, although I have been told that many firewalls have similar timeouts. Certainly, any AWS customer that connects through their Gateway Load Balancer to an on premises Oracle database would need to know this sort of thing. Hopefully, we are not the only ones in the world doing it this way! But at least I documented it for myself which will be helpful no matter what.
Bobby
350 Second Timeout Causes ORA-03135 Errors in AWS DMS
This is a follow up to an earlier post about the 350 second timeout that is built into Amazon Web Services’ (AWS) Gateway Load Balancer (GWLB).
The earlier post was about Debezium (DBZ) using its Oracle Connector to pull data from an on-premises Oracle database into Kafka in AWS. DBZ used JDBC to connect to the Oracle database so I built a simple Java program that uses JDBC to mimic the behavior we saw in DBZ. With DBZ we were hanging if any SQL statement that DBZ ran took >= 350 seconds to run. If it did, then the Oracle session hung and Debezium never got past that SQL statement.
But for AWS Database Migration Service (DMS) the symptoms were different. For DMS I could not find any SQL statement that ran for >= 350 seconds. All the SQL statements ran much faster. But we did see ORA-03135 errors in DMS’s log like this:
DMS seemed to be waiting >= 350 seconds between SQL statements in certain cases, maybe doing a large load, and that seemed to be causing the ORA-03135 errors. I also saw DMS Oracle sessions waiting for more than 350 seconds on “SQL*Net message from client” idle waits. These seemed to eventually go away after 6000 or more seconds. I think that the GWLB was silently dropping the network connection, but the Oracle sessions still existed until at some point they realized that the network connection was gone. But I wanted to recreate the problem in a simple test case to prove that the 350 second GWLB timeout would throw the ORA-03135 error and leave the DMS Oracle sessions hanging for several thousand seconds in the SQL*Net wait that I was seeing in our production DMS sessions.
To recreate this error and the orphaned session behavior and to show that it was due to the GWLB 350 second timeout and not some other weird network problem I did some simple tests with SQL*Plus and Instant Client. I installed these on an AWS EC2 Linux machine that already had the firewall and security group configuration setup to allow a connection from the EC2 to an on-premises Oracle database. Then I just logged into that database and sat idle for different lengths of time before running a select statement. I narrowed it down to about 350 seconds as the cutoff point where the session is lost due to too much idle time.
Here is my test with < 350 second wait:
SQL> connect myuser/mypassword@mydatabase
Connected.
SQL> host sleep 348
SQL> select * from dual;
D
-
X
Elapsed: 00:00:00.11Here is my test with > 350 seconds wait:
SQL> connect myuser/mypassword@mydatabase
Connected.
SQL> host sleep 351
SQL> select * from dual;
select * from dual
*
ERROR at line 1:
ORA-03135: connection lost contact
Process ID: 1208
Session ID: 57 Serial number: 21111Narrowing it down to 350 seconds at the cutoff showed that just logging in and waiting for > 350 seconds causes an ORA-03135 error. I also verified that the associated Oracle sessions hung around for > 350 seconds stuck on the “SQL*Net message from client” wait. Sure, DMS could be throwing a ORA-03135 error due to some unrelated network problem, but my SQL*Plus test proved that any Oracle connection from our AWS environment back to our on-premises Oracle databases will throw a ORA-03135 error and leave orphaned Oracle sessions if it sits idle for >= 350 seconds unless we put the fix in place that I mentioned in my earlier post.
The fix is to set the Linux parameter net.ipv4.tcp_keepalive_time to < 350 seconds and to use (ENABLE=BROKEN) in your connection strings. Once I put these in place for my SQL*Plus test I could wait longer than 350 seconds and then run a select statement with no errors.
Since March when we noticed this timeout with Debezium I have suspected the timeout would also affect DMS, but I did not know that the symptoms would be throwing ORA-03135 errors and leaving orphaned sessions when the time idle between SQL statements exceeded the timeout. It took a few tickets working with AWS support but last week they put net.ipv4.tcp_keepalive_time < 350 seconds and (ENABLE=BROKEN) in their global DMS configuration for all their customers.
So, from now on anyone setting up a new DMS replication instance version 3.4.5 or later should be able to replicate data from AWS to an on-premises Oracle database through Amazon’s Gateway Load Balancer without facing these ORA-03135 errors. If you created your replication instance before last week you should create a new one >= version 3.4.5 to take advantage of this fix, especially if you are seeing ORA-03135 errors in your logs.
Bobby
Docker Sample Application behind Zscaler
I am trying to learn about Docker by installing it on an Oracle Linux 7 VM on top of VirtualBox on my work laptop. My work laptop uses Zscaler. I had a bunch of certificate issues and ended up learning a lot about Docker by working around them. I tried to do the Sample Application – really the simplest first step in the Docker documentation – and had all kinds of trouble getting it to work. Ultimately, I ended up with a Dockerfile that looked like this:
[root@docker ~]# cat Dockerfile
# syntax=docker/dockerfile:1
FROM oraclelinux:7
COPY z.pem /etc/pki/ca-trust/source/anchors/z.pem
RUN update-ca-trust
RUN echo sslverify=false >> /etc/yum.conf
RUN yum install -y oracle-nodejs-release-el7 oracle-release-el7
RUN yum install -y nodejs
RUN npm install -g npm
RUN npm install -g yarn
WORKDIR /app
COPY . .
RUN yarn config set "strict-ssl" false -g
RUN yarn install --production
CMD ["node", "src/index.js"]
EXPOSE 3000
By contrast the Dockerfile that was supposed to work looks like this:
# syntax=docker/dockerfile:1
FROM node:12-alpine
RUN apk add --no-cache python2 g++ make
WORKDIR /app
COPY . .
RUN yarn install --production
CMD ["node", "src/index.js"]
EXPOSE 3000I ended up using the oraclelinux:7 image because it had more stuff installed such as update-ca-trust. Because I could not get anything to work with Zscaler I had to start with an image that did not require me to pull more stuff down with yum. Then, after playing with it I still ended up disabling SSL verification on yum and yarn. I had to install node since I was starting with a plain Linux image and not a node image.
I had these instructions for getting Zscaler to work on my Oracle Linux 7 VirtualBox VMs on my company computer:
Had to extract Zscaler .cer root ca from Chrome browser as z.cer.
Moved to linux and ran:
openssl x509 -inform der -in z.cer -outform der -out z.pem
copied z.pem to /etc/pki/ca-trust/source/anchors/
ran
update-ca-trust
worked.I do not know if this is really doing anything. It affects curl so that I can use curl without the -k option to disable SSL verification. Maybe things that use curl under the covers are affected by adding z.pem to the trusted certificates.
Anyway, I just wanted to document this for myself. Maybe someone out there will benefit also.
Bobby
350 second AWS timeout causes JDBC call to hang
When I run the following Java program on an AWS EC2 Linux virtual machine connecting to an Oracle database in my company’s internal network it hangs forever.
When I run it on a Linux machine on our internal network it runs fine.
Evidently my company uses an AWS feature called “Gateway Load Balancer” to connect our AWS network to our internal on premises network. Evidently the GLB has a 350 second timeout. See this document:
Here is a quote of the relevant paragraph:
Some applications or API requests, such as synchronous API calls to databases, have long periods of inactivity. GWLB has a fixed idle timeout of 350 seconds for TCP flows and 120 seconds for non-TCP flows. Once the idle timeout is reached for a flow, it is removed from GWLB’s connection state table. As a result, the subsequent packets for that flow are treated as a new flow and may be sent to a different healthy firewall instance. This can result in the flow timing out on the client side. Some firewalls have a default timeout of 3600 seconds (1 hour). In this case, GWLB’s idle timeout is lower than the timeout value on the firewall, which causes GWLB to remove the flow without the firewall or client being aware it was dropped.
Best practices for deploying Gateway Load BalancerThis means that my JDBC call using the thin driver will work fine if I sleep for 349 seconds but will hang forever if I try to sleep for 350 seconds. The solution is to update a Linux operating system parameter and to update the JDBC connect string.
OS:
sysctl -w net.ipv4.tcp_keepalive_time=60
add this line to /etc/sysctl.conf:
net.ipv4.tcp_keepalive_time=60Evidently our default tcp_keepalive_time value was 7200 seconds which is longer than the 350 second timeout so we had to lower it to 60 seconds to that the Gateway Load Balancer would know that our JDBC call was actually doing something.
You have to add (ENABLE=broken) to the jdbc connect string like this:
jdbc:oracle:thin:MYUSER/MYPASSWORD!@(DESCRIPTION=(ENABLE=broken)(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(Host=myhost)(Port=1521)))(CONNECT_DATA=(SERVICE_NAME=MYSERVICE)))Once I did this my Java test program worked fine. It ran for about 350 seconds and finished cleanly.
If you are working in AWS and connecting to a on premises database using JDBC and you have a SQL statement that should run for 350 seconds or more and hangs forever you might check whether you are being affected by this timeout.
Bobby
p.s. I forgot to mention that the Oracle database session goes away after 350 seconds. It is just the client side JDBC call that hangs apparently forever.
p.p.s. We have a related issue with Putty sessions connecting to Amazon EC2 Linux VMs timing out after 350 seconds. A coworker offered this article as a solution:
https://patrickmn.com/aside/how-to-keep-alive-ssh-sessions/
The Putty keepalives setting works great!
Another coworker of mine was saying that certain types of firewalls work this way with timeouts. The problem is that the GWLB times out our on-premises side but not our AWS side. So, in the case of using Putty to ssh into an EC2 that does not have keepalives configured my Putty session, which also does not have keepalives configured, times out after 350 seconds of idle time. When I hit enter, I get “Network error: Software caused connection abort” but if I check my BASH shell process id, I see that my shell process was never terminated. So, old processes hang around forever on my EC2 if the ssh connection times out due to the GWLB 350 second timeout.
Maybe it is normal for connections on one side of a firewall to time out and the other side to hang forever? I am not sure.
Do SET_AUDIT_TRAIL_LOCATION before INIT_CLEANUP
This is all old stuff, but I want to record a simple thing I found. I was following Oracle’s support document for setting up audit table cleanup using the DBMS_AUDIT_MGMT package. I used this document:
SCRIPT: Basic example to manage AUD$ table with dbms_audit_mgmt (Doc ID 1362997.1)
This is a very helpful document, but the example script runs DBMS_AUDIT_MGMT.INIT_CLEANUP before it runs DBMS_AUDIT_MGMT.SET_AUDIT_TRAIL_LOCATION and it moves the audit tables SYS.AUD$ first to the SYSAUX tablespace and then to a newly created AUDIT_DATA tablespace. My simple thought is to run SET_AUDIT_TRAIL_LOCATION first to move SYS.AUD$ to AUDIT_DATA and then run INIT_CLEANUP which leaves SYS.AUD$ in AUDIT_DATA. Nothing monumental, but it seems more efficient to move the audit table once.
I did a couple of quick tests on an 18c database to demonstrate that SYS.AUD$ only moves once with SET_AUDIT_TRAIL_LOCATION first.
Test1: Follow the order in the Oracle document:
Before starting:
SQL> select 2 tablespace_name 3 from dba_tables 4 where 5 owner='SYS' and 6 table_name='AUD$'; TABLESPACE_NAME ------------------------------ SYSTEM
Create tablespace:
SQL> CREATE TABLESPACE AUDIT_DATA LOGGING DATAFILE '/oracle/db01/DBA18C/dbf/audit_data_1.dbf' SIZE 100M AUTOEXTEND OFF; 2 3 4 Tablespace created.
Do INIT:
SQL> BEGIN
2 IF NOT DBMS_AUDIT_MGMT.IS_CLEANUP_INITIALIZED
3 (DBMS_AUDIT_MGMT.AUDIT_TRAIL_AUD_STD)
4 THEN
5 dbms_output.put_line('Calling DBMS_AUDIT_MGMT.INIT_CLEANUP');
6 DBMS_AUDIT_MGMT.INIT_CLEANUP(
7 audit_trail_type => dbms_audit_mgmt.AUDIT_TRAIL_AUD_STD,
8 default_cleanup_interval => 24*7);
9 else
10 dbms_output.put_line('Cleanup for STD was already initialized');
11 end if;
12 end;
13 /
Calling DBMS_AUDIT_MGMT.INIT_CLEANUP
PL/SQL procedure successfully completed.
Table in SYSAUX:
SQL> select 2 tablespace_name 3 from dba_tables 4 where 5 owner='SYS' and 6 table_name='AUD$'; TABLESPACE_NAME ------------------------------ SYSAUX
Set the new table location:
SQL> begin 2 DBMS_AUDIT_MGMT.SET_AUDIT_TRAIL_LOCATION( 3 audit_trail_type => dbms_audit_mgmt.AUDIT_TRAIL_AUD_STD, 4 audit_trail_location_value => 'AUDIT_DATA') ; 5 end; 6 /
Table is in AUDIT_DATA (moved twice SYSTEM->SYSAUX->AUDIT_DATA):
SQL> select 2 tablespace_name 3 from dba_tables 4 where 5 owner='SYS' and 6 table_name='AUD$'; TABLESPACE_NAME ------------------------------ AUDIT_DATA
Test2: Reverse the order in the Oracle document:
First, I restored my database to its original condition:
SQL> select 2 tablespace_name 3 from dba_tables 4 where 5 owner='SYS' and 6 table_name='AUD$'; TABLESPACE_NAME ------------------------------ SYSTEM
After creating the tablespace again, I ran set the trail location and the table is now in AUDIT_DATA:
SQL> select 2 tablespace_name 3 from dba_tables 4 where 5 owner='SYS' and 6 table_name='AUD$'; TABLESPACE_NAME ------------------------------ AUDIT_DATA
Next, I do the init and the table does not move:
SQL> select 2 tablespace_name 3 from dba_tables 4 where 5 owner='SYS' and 6 table_name='AUD$'; TABLESPACE_NAME ------------------------------ AUDIT_DATA
So, I am not sure why Oracle’s document has you do INIT_CLEANUP before SET_AUDIT_TRAIL_LOCATION but it seems more efficient to do them in the reverse order and move SYS.AUD$ once, from SYSTEM to AUDIT_DATA.
Bobby
Oracle 21c Laptop Install
Finally got around to installing Oracle 21c on my laptop. I installed it on Oracle’s Linux version 7 running in VirtualBox. There are other posts out there, so I won’t get too detailed. I noticed this post:
https://oracle-base.com/articles/21c/oracle-db-21c-installation-on-oracle-linux-7
But I mainly went by the manual:
https://docs.oracle.com/en/database/oracle/oracle-database/21/ladbi/index.html
I stopped the firewall:
service firewalld stop systemctl disable firewalld
I used the preinstall yum package:
yum install oracle-database-preinstall-21c
As root setup the directories with the right ownership and permission:
mkdir -p /u01/app/oracle mkdir -p /u01/app/oraInventory chown -R oracle:oinstall /u01/app/oracle chown -R oracle:oinstall /u01/app/oraInventory chmod -R 775 /u01/app
As oracle unzipped the zip:
cd /u01/app/oracle/product/21.0.0/dbhome_1 unzip -q /home/oracle/LINUX.X64_213000_db_home.zip
I was annoyed by the -q option of unzip. If I did it again, I would leave it off so that I could see the list of files as they were unzipped.
From the console I ran this:
cd /u01/app/oracle/product/21.0.0/dbhome_1 ./runInstaller
I got a warning about the clock source being kvm-clock and not tsc. I tried Oracle’s instructions to fix this warning, but they did not work for me. It was just a warning apparently coming from the cluster verification utility. Since I am not using RAC, I didn’t see how this could matter so I ignored it. The install was very simple. Forced to use a CDB this time as I already knew.
The only interesting part for me was the read only Oracle home. Evidently the files that are updatable are stored under ORACLE_BASE_HOME instead of ORACLE_HOME.
I ended up adding these lines to .bash_profile:
export ORACLE_SID=orcl export ORAENV_ASK=NO . oraenv export ORACLE_BASE_HOME=/u01/app/oracle/homes/OraDB21Home1
To add a new tnsnames.ora entry for the pdb I had to go to $ORACLE_BASE_HOME/network/admin instead of $ORACLE_HOME/network/admin:
[oracle@orcl21 ~]$ ls -altr $ORACLE_HOME/network/admin total 4 -rw-r--r--. 1 oracle oinstall 1624 Feb 18 2020 shrept.lst drwxr-xr-x. 2 oracle oinstall 61 Jul 27 2021 samples drwxr-xr-x. 10 oracle oinstall 98 Jul 27 2021 .. drwxr-xr-x. 3 oracle oinstall 37 Jan 26 13:45 . [oracle@orcl21 ~]$ ls -altr $ORACLE_BASE_HOME/network/admin total 16 drwxr-x---. 5 oracle oinstall 40 Jan 26 12:52 .. -rw-r-----. 1 oracle oinstall 190 Jan 26 12:53 sqlnet.ora -rw-r-----. 1 oracle oinstall 329 Jan 26 12:53 listener.ora -rw-r-----. 1 oracle oinstall 397 Jan 26 13:49 tnsnames.ora.01262022 -rw-r-----. 1 oracle oinstall 586 Jan 26 13:49 tnsnames.ora drwxr-x---. 2 oracle oinstall 89 Jan 26 13:49 .
I added this entry to $ORACLE_BASE_HOME/network/admin/tnsnames.ora:
orclpdb =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = orcl21)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = orclpdb)
)
)
Pretty simple. The hard part is understanding what is new in 21c.
Bobby
Dropping sequences whose name starts with ISEQ$$
We had an application that created 500,000 tables and 500,000 sequences and the vendor sent us a cleanup script that we thought would drop the tables but not the sequences. It took us a few attempts to get a cleanup script that looked like it would work with the tables, but the sequences seemed totally wrong. The tables had dashes in their names and a bunch of random characters between the dashes and the cleanup script looked for that pattern. But the sequence names all started with ISEQ$$ and they were trying to drop sequences whose names were like the tables’ names. Confusing. Finally, they convinced us to run the script whether it looks like it would work or not. After tweaking it a bit it did run and dropped both the tables and the sequences. What in the world? Then I had a vague memory of something called “identity columns” probably from my 12.1 certification. I do not think I have seen them in a real system, so I checked the tables and sure enough they all had a single identity column and each sequence matched up with each table. So, when we dropped the tables, the sequences went with them. I do not know why I did not clue into the fact that the sequences have dollar signs $$ in their name which means they were probably system generated. Duh!
I thought about not posting anything about this because I was sure there were several good posts out there about this and there are. So, I will link some of them below and not try to recreate them. The funny thing is that the DBAs at the vendor kept talking about flushing the recycle bin to drop the sequence and that also made no sense at the time. Why would flushing the dropped tables out of the recycle bin have anything to do with the sequences? But as you will see in the posts it does.
One thing that probably is not in the posts is that if you turn off the recycle bin with a parameter then dropping the table drops the sequence that is associated with its identity column without having to clear the recycle bin or do a drop table purge. We have this parameter set:
SQL> show parameter recyclebin NAME TYPE VALUE ------------------------------------ ----------- ----------------- recyclebin string OFF
Here is my simple test script and its output: zip
I used drop table purge in the test script, so it works even if the recycle bin is enabled. If you run the blog.sql script in the zip, be sure to run it as a user that does not have any tables.
Here are the blog posts:
https://oracle-base.com/articles/12c/identity-columns-in-oracle-12cr1
This is from Tim Hall’s Oracle Base which has a fantastic amount of detail about various Oracle features and versions. It shows the ISEQ$$ sequence names. Why didn’t I just google ISEQ$$?
https://floo.bar/2019/11/29/drop-the-underlying-sequence-of-an-identity-column/
This talks about how to drop the sequence by dropping the table and either clearing the recycle bin or using drop table purge.
https://stackoverflow.com/questions/58984546/cannot-drop-a-system-generated-sequence/58984939
This SO question has a nice answer similar to the previous post.
Covers a lot of ground but talks about the recycle bin.
Anyway, I wanted to note these posts/links as well as my experience. If you want to drop sequences with names starting with ISEQ$$ you need to drop the associated table with an identity column and be sure to purge the table from the recycle bin if you have it enabled.
Bobby
latch: shared pool waits after patching to 19.13
I have been working hard on an issue that happened after we patched an Oracle database to the 19.13 patch set which just came out in October. The application experienced a ton of latch: shared pool waits, and the patch set had to be backed out. Currently the database is running on the 19.5 patch set and running fine. I have been trying to figure this out on my own and I have been working with Oracle support but so far, I have not come up with a proven resolution. But I thought I would document what I know here before I go off on vacation for two weeks around the Christmas and New Year holidays.
It all started on October 26th when we were still on 19.5 and our application hung up with alert log messages consistent with this bug:
Bug 30417732 – Instance Crash After Hitting ORA-00600 [kqrHashTableRemove: X lock] (Doc ID 30417732.8)
Here were the error messages:
One of these:
ORA-00600: internal error code, arguments: [kqrHashTableRemove: X lock], [0x11AA5F3A0]Then a bunch 0f these:
ORA-00600: internal error code, arguments: [kglpnlt]I found that the fix for bug 30417732 is in the 19.9 and later patch sets. So, I, perhaps foolishly, decided to apply the latest patch set (19.13) after testing it in our non-production databases. In retrospect I probably should have found a one-off patch for 30417732 but I wanted to catch up to the latest patch set and be on the current and hopefully most stable version of Oracle.
So after applying 19.13 in our lower environments and testing there we applied it on production on November 13th and we had poor performance in the application Monday through Thursday and finally backed out the patch set Thursday night. It has been fine ever since and the original problem, bug 30417732, has fortunately not happened again.
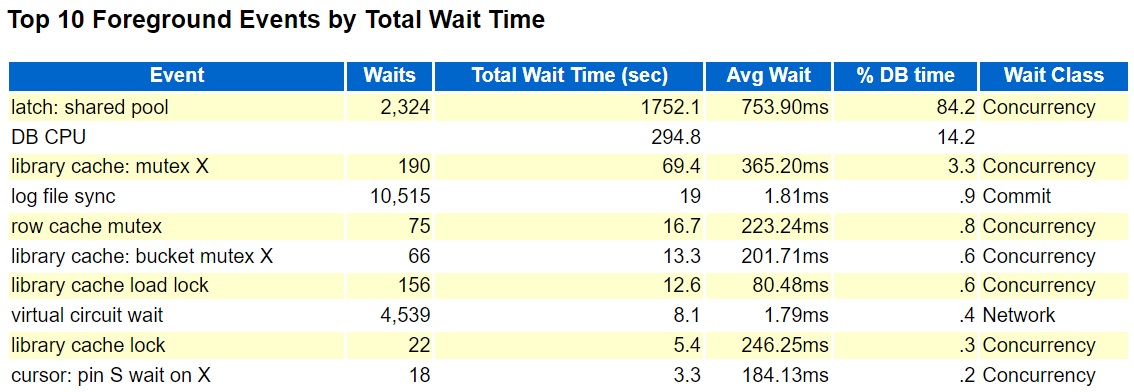
I generated an AWR report during an hour when the problem was occurring, and it showed latch: shared pool as the top foreground event. Like this:
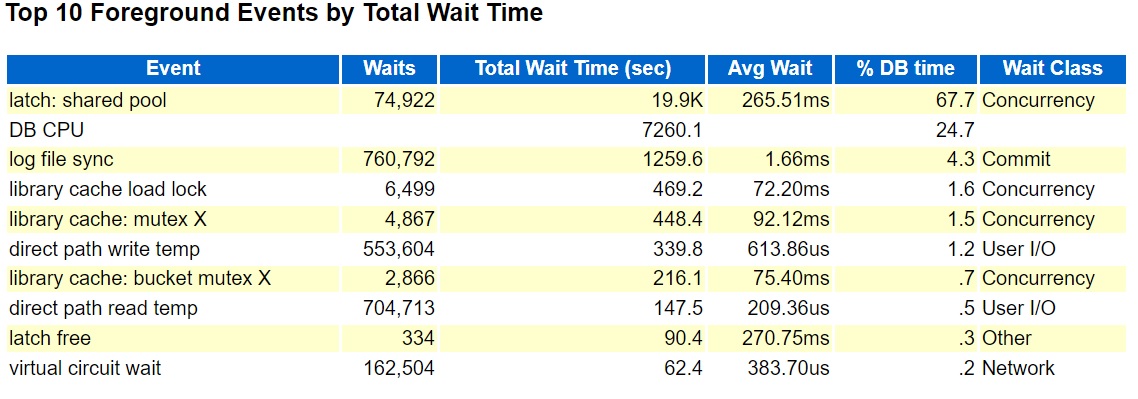 Top Foreground Events
Top Foreground Events
I was able to use my onewait.py and sessioncounts.py to show a correlation between the number of connected sessions and the number of latch waits.
Latch waits:
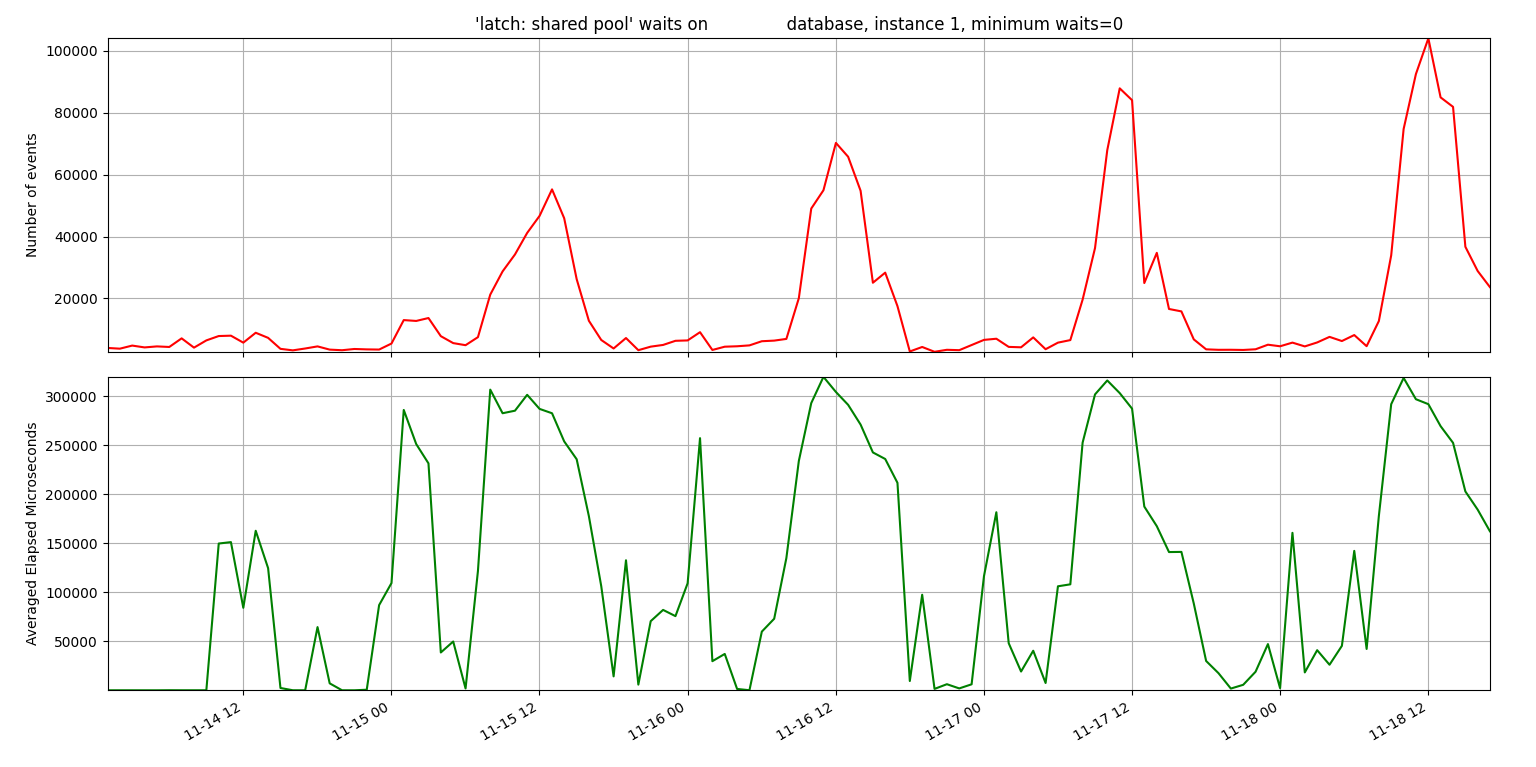 latch: shared pool waits
latch: shared pool waits
Number of connected sessions:
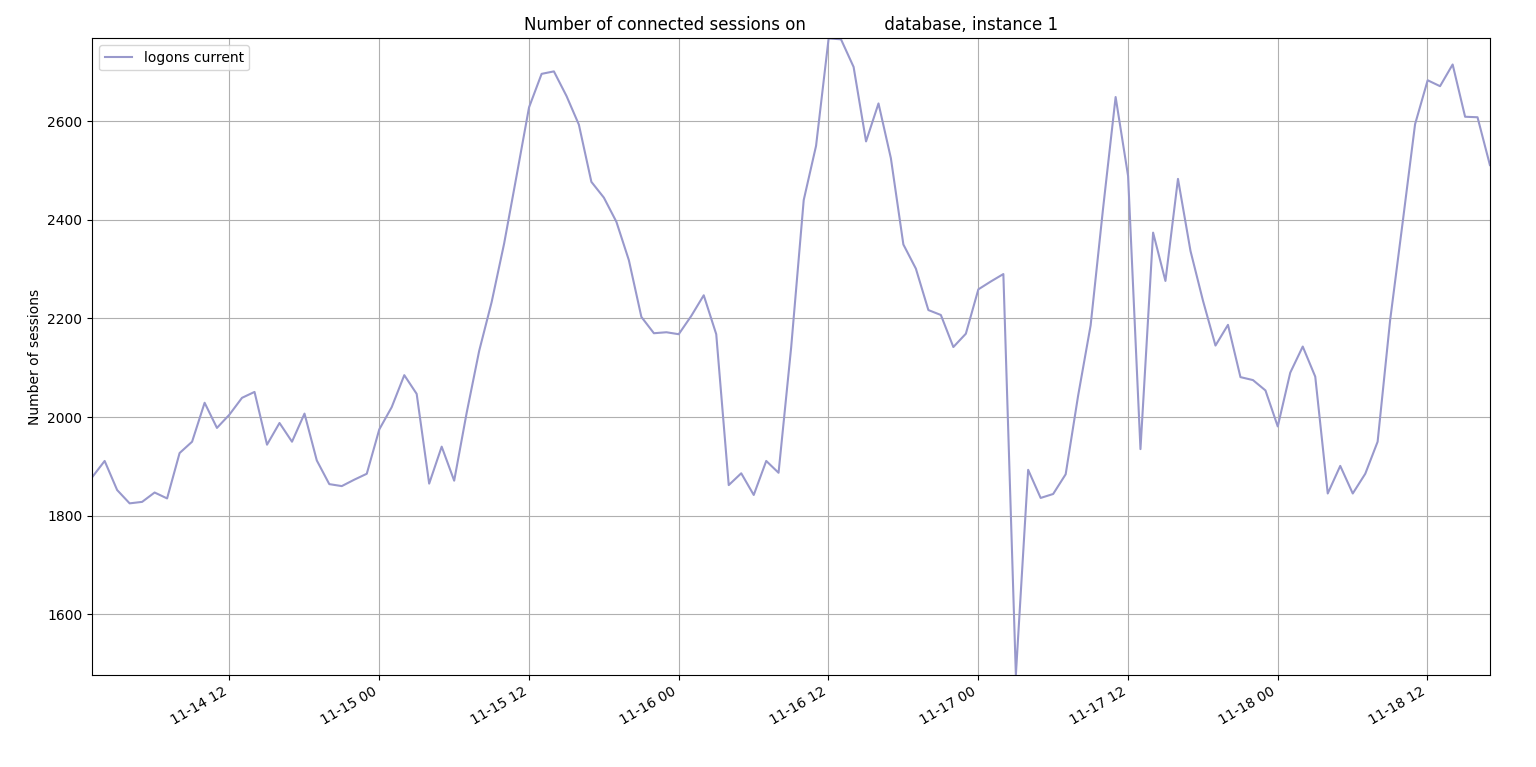 Number of sessions
Number of sessions
This database uses shared servers which uses memory in the shared pool and large pool so it makes sense that a bunch of logins might cause some contention for the shared pool. I tried to recreate the high latch: shared pool waits on a test database by running a Java script that just creates 1000 new sessions:
This did result in similar or even worse latch: shared pool waits during the time the Java script was running:
So, I have been able to recreate the problem in a test database but now I am stuck. This is not a minimal reproducible example. The test database is actively used for development and testing. I have tried to create my own load to apply to a small database but so far, I cannot reproduce the exact results. If I run 10 concurrent copies of MaxSessions.java I can get latch: shared pool waits on a small database, but I get the same behavior on 19.5 as I do on 19.13. So, something is missing. Here is a spreadsheet of my test results:
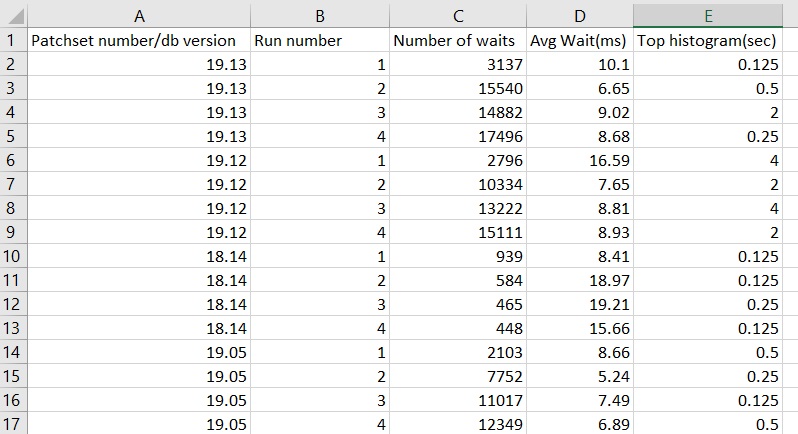 Results from running 10 Java processes
Results from running 10 Java processes
19.5, 19.12, and 19.13 have the same results but 18.14 is a lot better. I was trying to come up with a test that was a lot better on 19.5 than 19.13 but I have not succeeded.
I have looked at a boatload of other things not listed here but I am running out of steam. Friday is my last day working until January 4th, so I hope to put this out of my mind until then. But I thought it was worth using this blog post to document the journey. Maybe at some point I will be able to post a positive update.
Bobby
12/16/21
Made some progress working with Oracle support on this yesterday. I did not mention in this post that the latch behind all the latch: shared pool waits was
kghfrunp: alloc: waitHere is the top latch from the AWR report:
 Top Latch Name
Top Latch Name
An Oracle analyst noted that this bug also involves the same latch:
Bug 33406872 : LATCH SHARED POOL CONTENTION AFTER UPGRADE TO 19.12
I had noticed bug 33406872 but I did not know that it was on the kghfrunp: alloc: wait latch because that information is not visible to Oracle customers.
The same analyst had me rerun the Java script listed above but with a dedicated server connection. I did and it did not have the latch waits. So, this is a shared server bug.
Oracle development is working on it so there is no fix yet but here is the situation as it seems to be now: If you are using shared servers on 19.12 or 19.13 and have high latch: shared pool waits on the kghfrunp: alloc: wait latch you may be hitting a new bug that Oracle is working on.
1/7/2022
After getting back from 2 weeks vacation I took another crack at this and I think I have come up with a useful test case for the SR. Time will tell, but it looks promising. I added a second Java script to the MaxSessions one listed above. Here it is:
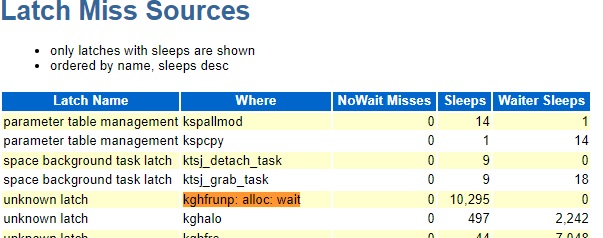
This opens 1000 shared server sessions and then runs unique select statements on each of the 1000 sessions one at a time looping up to 1000 times. After about 60 loops I get the latch: shared pool waits. I tried this on both 19.13 and 19.5 and I get the waits in both but with differences.
19.13 after 100 loops:

19.5 after 100 loops

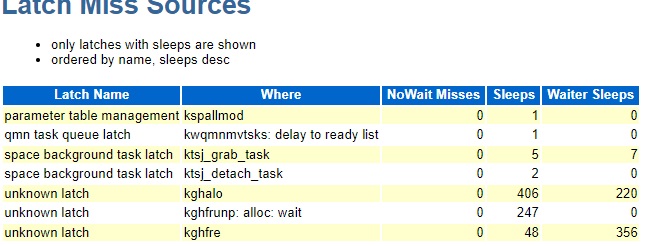
Avg Wait, % DB time, and sleeps for the kghfrunp: alloc: wait latch were all higher on 19.13.
Note that I had to keep the GenLoad.java script running while I ran MaxSessions.java and I took AWR snapshots around the MaxSessions run to get these AWR report outputs.
Maybe this will be enough to help Oracle recreate this behavior internally.
Bobby
10/24/22
Back from a weeklong cruise vacation and Oracle support says that they opened bug 33801843 for this issue and that it will be fixed in a future release. I would not use shared servers going forward after 19.11.
Outline Hint from dbms_xplan does not contain PARALLEL hint
I was tuning a parallel query and was a little surprised to find that an outline hint from EXPLAIN PLAN and dbms_xplan.display did not contain a PARALLEL hint. So, a query I was testing did not run in parallel with the outline hint. I had to add the PARALLEL hint. It is surprising because I think of an outline hint as a full set of hints.
I built a testcase to demonstrate this. Here is a zip of its script and output on a 19c database: blogparalleloutlinehints.zip.
I created a small test table and got the outline for the plan of a select statement with a parallel hint:
drop table test;
create table test noparallel as select * from dba_tables;
explain plan into plan_table for
select /*+ parallel(test,8) */ sum(blocks) from test;
set markup html preformat on
select * from table(dbms_xplan.display('PLAN_TABLE',NULL,'ADVANCED'));
The outline hint looks like this:
/*+
BEGIN_OUTLINE_DATA
FULL(@"SEL$1" "TEST"@"SEL$1")
OUTLINE_LEAF(@"SEL$1")
ALL_ROWS
DB_VERSION('19.1.0')
OPTIMIZER_FEATURES_ENABLE('19.1.0')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/
Notice that it just has a FULL hint and nothing about running the query in parallel.
Next, I ran the query with the outline hint but without any parallel hint like this:
select /*+
BEGIN_OUTLINE_DATA
FULL(@"SEL$1" "TEST"@"SEL$1")
OUTLINE_LEAF(@"SEL$1")
ALL_ROWS
DB_VERSION('19.1.0')
OPTIMIZER_FEATURES_ENABLE('19.1.0')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/ sum(blocks) from test;
It ran with a serial (non-parallel) plan:
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 27 (100)| |
| 1 | SORT AGGREGATE | | 1 | 3 | | |
| 2 | TABLE ACCESS FULL| TEST | 1785 | 5355 | 27 (0)| 00:00:01 |
---------------------------------------------------------------------------Then I ran the query with both a parallel hint and the same outline hint:
select /*+ parallel(test,8)
BEGIN_OUTLINE_DATA
FULL(@"SEL$1" "TEST"@"SEL$1")
OUTLINE_LEAF(@"SEL$1")
ALL_ROWS
DB_VERSION('19.1.0')
OPTIMIZER_FEATURES_ENABLE('19.1.0')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/ sum(blocks) from test;It ran the desired parallel plan:
-------------------------------------------...---------------------
| Id | Operation | Name |...|IN-OUT| PQ Distrib |
-------------------------------------------...---------------------
| 0 | SELECT STATEMENT | |...| | |
| 1 | SORT AGGREGATE | |...| | |
| 2 | PX COORDINATOR | |...| | |
| 3 | PX SEND QC (RANDOM) | :TQ10000 |...| P->S | QC (RAND) |
| 4 | SORT AGGREGATE | |...| PCWP | |
| 5 | PX BLOCK ITERATOR | |...| PCWC | |
|* 6 | TABLE ACCESS FULL| TEST |...| PCWP | |
-------------------------------------------...---------------------
In other tuning situations with plans that did not execute in parallel the outline hints from dbms_xplan.display_cursor did a great job of capturing all the details of the plan. But when extracting an outline hint from a query that has a parallel hint in it, I needed both the outline hint and the parallel hint to get the same plan.
Bobby
Tuning Example With Outline Hints and SQL Profile
I tuned a production query this week using outline hints and a SQL profile. This is like other examples I have posted but may have enough differences to be worth documenting here.
A query in a batch job was taking over an hour to run. I got it to run in under 30 minutes.
Old plan
898524 rows selected.
Elapsed: 01:13:34.35
New plan
899018 rows selected.
Elapsed: 00:28:00.28
The new plan ran about 45 minutes faster.
The main point here is that I was able to improve the plan in a more selective way using an outline hint than I could have with regular hints.
I ran the problem query using my test2.sql script to show the expected and actual number or rows in each step in the plan and to show the amount of time spent on each step. The output looked like this:
This is the typical example of a bad plan using an index in a case where a full scan is more efficient. Most of the time is spent in step 4 doing 898 thousand table lookups. So, to fix this query I tried a FULL hint to get rid of the SKIP SCAN, but it did not help. I tried various combinations of FULL hints on the four tables in the plan and they all resulted in inefficient plans with different types of joins than the original plan.
Full hints:
SELECT /*+ FULL(DD) FULL(ORG) FULL(WINDOW1) FULL(WINDOW2) */
DD.ROW_ID
...
Plan:
-----------------------------------------------
| Id | Operation | Name |
-----------------------------------------------
| 0 | SELECT STATEMENT | |
|* 1 | HASH JOIN RIGHT OUTER | |
|* 2 | TABLE ACCESS FULL | S_ORG_EXT_XM |
|* 3 | HASH JOIN RIGHT OUTER| |
|* 4 | TABLE ACCESS FULL | S_ORG_EXT_XM |
|* 5 | HASH JOIN | |
|* 6 | TABLE ACCESS FULL | S_ORG_EXT |
|* 7 | TABLE ACCESS FULL | S_ORG_EXT_XM |
-----------------------------------------------
Then I got the idea of using an outline hint. The plan.sql script that I use to run EXPLAIN PLAN on a query outputs an outline hint. In this case the outline hint looks like this:
The main idea that I wanted to write this post about is to take this outline hint and leave everything else the same but to replace the skip scan with a full table scan. Adding a FULL hint was changing a lot of things about the plan. But if I start with the outline hint, I can force the plan to remain the same except for the one thing I change. I ran plan.sql with the query with a full hint to get the outline with a full scan and then pulled out just the full scan line to put into the original plan’s outline. Here are the old and new lines that I used to edit to outline hints for the original query’s plan, an index skip scan and a full table scan.
Old:
INDEX_SS(@"SEL$1" "DD"@"SEL$1" ("S_ORG_EXT_XM"."PAR_ROW_ID" "S_ORG_EXT_XM"."TYPE"
"S_ORG_EXT_XM"."NAME" "S_ORG_EXT_XM"."CONFLICT_ID"))
New:
FULL(@"SEL$1" "DD"@"SEL$1")Here is the edited version of the outline hint:
So, then I ran my test2.sql script but with the edited outline hint and the query ran in 28 minutes. So, all we had to do was put the outline hint into the existing SQL script.
But then I realized that I could finish off the performance improvement using a SQL Profile and not have to edit the script. The output for the run of my test2.sql script with the hint had this sql_id and plan_hash_value: 3m80wvb2v6vdq 42036438.
My slow production query had this sql id and plan hash value: dzfr3vz7z5p66 2238264355.
So, I passed these two sets of parameters to coe_xfr_sql_profile.sql in the sqlt/utl subdirectory creating these two scripts:
coe_xfr_sql_profile_3m80wvb2v6vdq_42036438.sql
and
coe_xfr_sql_profile_dzfr3vz7z5p66_2238264355.sqlSo, I hacked the two scripts together to make coe_xfr_sql_profile_dzfr3vz7z5p66_42036438.sql which has the SQL text of the original query and the plan that my test script with the outline hint used. The scripts output by coe_xfr_sql_profile.sql save the text of the SQL statement and its plan when creating a new SQL Profile. You can get a little creative and connect production SQL text with a plan you have generated through hints.
9 DBMS_LOB.CREATETEMPORARY(sql_txt, TRUE);
10 DBMS_LOB.OPEN(sql_txt, DBMS_LOB.LOB_READWRITE);
11 -- SQL Text pieces below do not have to be of same length.
12 -- So if you edit SQL Text (i.e. removing temporary Hints),
13 -- there is no need to edit or re-align unmodified pieces.
14 wa(q'[SELECT DD.ROW_ID|| '||' ||
15 DD.PAR_ROW_ID|| '||' ||
text of original query starts line 14
55 AND WINDOW2.X_DELIV]');
56 wa(q'[ERY_WINDOW (+) = '2'
57 AND WINDOW2.TYPE (+)= 'DELIVERY TIMES']');
58 DBMS_LOB.CLOSE(sql_txt);
59 h := SYS.SQLPROF_ATTR(
60 q'[BEGIN_OUTLINE_DATA]',
61 q'[IGNORE_OPTIM_EMBEDDED_HINTS]',
text of query ends line 57. outline hint with full scan starts line 60
80 q'[USE_MERGE(@"SEL$1" "ORG"@"SEL$1")]',
81 q'[END_OUTLINE_DATA]');
82 :signature := DBMS_SQLTUNE.SQLTEXT_TO_SIGNATURE(sql_txt);
83 :signaturef := DBMS_SQLTUNE.SQLTEXT_TO_SIGNATURE(sql_txt, TRUE);
ends line 81So, I ran the edited coe_xfr_sql_profile_dzfr3vz7z5p66_42036438.sql to put in the SQL Profile which related the production query to the plan generated by the edited outline hint and the production job ran in 28 minutes last night without any change to its SQL code. The outline hint allowed me to leave the original plan intact except for the one step that needed a full scan instead of an index skip scan. Then the SQL Profile trick allowed me to apply the better plan without any change to the application.
Bobby
P.S. It looks like I didn’t have to hack together the sql profile script the way I did. See this post: https://www.bobbydurrettdba.com/2014/03/19/using-hints-with-coe_xfr_sql_profile-sql/
I could have just extracted the SQL Profile script like this:
coe_xfr_sql_profile.sql dzfr3vz7z5p66 42036438That would have generated oe_xfr_sql_profile_dzfr3vz7z5p66_42036438.sql automatically combining the production SQL text with the plan with the outline hint and full scan instead of me editing it together manually.
Two New ASH FORCE_MATCHING_SIGNATURE scripts
I just put two new scripts on my OracleDatabaseTuningSQL GitHub repository. These came out of a PeopleSoft Financials performance problem I was working on that involved a lot of similar SQL statements that used constants instead of bind variables, so they did not show up at the top of the AWR report. I had to look at ASH data to find them and had to group by their force matching signature to group the similar statements together. These are the two scripts:
ashfmscount.sql – Looks at a single application engine session and groups all the time spent by force matching signature to find the queries that consumed the most time. I used my simple ashdump.sql script to dump out a few rows when I knew the app engine was running and I found the SESSION_ID and SESSION_SERIAL# values there.
ashtopelapsed.sql – This is meant to look like the SQL by elapsed time report on an AWR report except that it groups SQL by force matching signature but gives an example sql id with its text to give you an idea of what the signature represents. Might be good to run this the next time my AWR report does not have any long running SQL statement on the top SQL report.
I really used the first one to resolve the issue along with various other scripts to get to that point. I created the second one just now as a possible future script to use in addition to an AWR report. I didn’t check the ASH report to see if this is a duplicate of it, but these two new scripts work well.
Bobby
Plan Change Due to Index Partition Names Mismatch
I want to document a bug I ran across in Oracle 11.2.0.3 on HP-UX Itanium and how it caused unexpected plan changes that would bring the database to its knees with many long running queries running the bad plan. I found that the problem table had a local index whose partition names did not match the partition names of the table and that recreating the index with partition names that matched the table resolved the issue.
We have a busy and important Oracle database that had queries that ran fine for weeks and months and then suddenly changed to a bad plan. They all had a similar pattern. The good plan did a simple range scan on a certain partition’s index. The bad plan did a fast full index scan.
Good:
PARTITION RANGE SINGLE |
INDEX RANGE SCAN | PROBLEM_INDEXBad:
PARTITION RANGE SINGLE |
INDEX FAST FULL SCAN | PROBLEM_INDEXThe query accessed the table using the first two columns of PROBLEM_INDEX and the first column of the index is the partitioning column for the range partitioned table. So, call the first two columns of the index PARTITIONING_C and OTHER_C then the query was like:
select
...
from problem_table
where
PARTITIONING_C = :bindvar1 and
OTHER_C = :bindvar2
...I have known for a long time that some choice of bind variable values was causing the plan to flip to the fast full scan on the index partition. But I did not know that it had to do with the names of the index’s partitions. The table and index creation scripts must have looked something like this:
create problem_table
(
PARTITIONING_C NUMBER,
OTHER_C NUMBER,
...
)
PARTITION BY RANGE (PARTITIONING_C)
(
PARTITION P1000 VALUES LESS THAN (1000),
PARTITION P2000 VALUES LESS THAN (2000),
PARTITION P3000 VALUES LESS THAN (3000),
PARTITION P4000 VALUES LESS THAN (4000),
PARTITION P5000 VALUES LESS THAN (5000));
CREATE UNIQUE INDEX problem_index ON problem_table
(PARTITIONING_C, OTHER_C , ...)
LOCAL (
PARTITION P2000,
PARTITION P3000,
PARTITION P4000,
PARTITION P5000,
PARTITION P6000);The index has the same number of partitions as the table and a lot of them have the same names, but they do not line up. I found this bug in the version of Oracle that we are on:
Bug 14013094 – DBMS_STATS places statistics in the wrong index partition
I am not sure that I am hitting that bug, but I am hitting some similar bug because 14013094 relates to index partitions names that do not match table partition names. For one partition of the problem index the statistics were set to 0 but its corresponding table partition had millions of rows. It would be as if partition P3000 on problem_table had 20,000,000 rows in stats and corresponding partition P4000 on problem_index had 0 rows. If I gathered index partition statistics on P4000 it correctly set stats to 20,000,000. If I gathered table partition statistics on P3000 it cleared the index partition stats on P4000 setting them to 0! (!!) Yikes! How weird is that? Seems obvious to me it is a bug, but maybe not exactly 14013094. I tried dropping and recreating the index leaving the partition names as they are, but it did not resolve the issue. Then I just created the index letting it default to matching partition names like this:
CREATE UNIQUE INDEX problem_index ON problem_table
(PARTITIONING_C, OTHER_C , ...)
LOCAL;I’m not sure how the partition names got mismatched but it is a simple fix. It took me a while staring at the partition statistics to realize what was going on and then it took a while to prove out the fix. We do not yet have this in production, but I believe we have nailed down the cause of the plan changes. In the past I have been using SQL Profiles to lock in the plans of any new query that uses the problem table, but I plan to run without them after putting in the index. I kick myself for not researching this earlier, but it was not obvious so maybe it was not crazy to use SQL Profiles for a while. But it became a burden to keep using them and it left the system vulnerable to a plan change on any query on the problem table that did not already have a SQL Profile.
In a lot of ways this is a simple query tuning problem with bad zero stats on a partition with millions of rows. Any time the statistics are wildly inaccurate bad plans are likely. But tracking down the reason for the zero statistics was not simple. I should mention that some of the table partitions are empty and have 0 rows. In fact, to take our example, imagine that table partition P4000 has 0 rows just like index partition P4000. No one would suspect that the statistics are wrong unless you realize that P4000 on the index corresponds not to P4000 but to P3000 on the table and P3000 has 20,000,000 rows!
Bind variables lead to these unexpected plan changes when the plan is different when different values are passed into the variables. It is a fundamental tradeoff of using bind variables to reduce the parsing that constants would cause. If one set of bind variable values causes a bad plan that plan gets locked into memory and it is used for all the other values passed to the query until the plan is flushed out of memory. There are some cases where the optimizer will look at the values passed into the bind variables and choose between multiple plans but that did not occur in this problem.
So, what can someone get from this post if they are not on 11.2.0.3 and do not have locally partitioned indexes with similar partition names to the table but offset and mismatched? I think for me the point is after using a SQL Profile to resolve a problem query plan to dig deeper into the underlying reason for the bad plan. I expect bad plans because I think that the optimizer is limited in its ability to correctly run a query even if it has the best possible statistics. Also, since I support many databases, I do not have time to dig deeply into the underlying reason for every bad plan. But I need to dig deeper when similar queries keep getting the same kind of bad plans. In many cases bad statistics lead to bad plans and it is a lot better to fix the statistics once than to keep using SQL Profiles and hints repeatedly to fix similar queries with the same sort of switches to bad plans. In this case I had the bizarre fix of recreating the index with partition names that match the table and that ensured that the statistics on the index partitions were accurate and that I no longer need SQL Profiles to lock in the good plan.
Bobby
MongoDB test server on Oracle Linux
I use Oracle Enterprise Linux on VirtualBox running on my Windows 10 laptop for test servers (virtual machines) of various types of software. I just setup a MongoDB VM yesterday and thought I would document some of the things I did which are not in the standard documentation.
I followed this URL for the install:
https://docs.mongodb.com/manual/tutorial/install-mongodb-on-red-hat/
I created the yum repository file mongodb-org-4.4.repo as documented:
[root@mongodb yum.repos.d]# cat mongodb-org-4.4.repo
[mongodb-org-4.4]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.4/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-4.4.asc
I installed the MongoDB yum package:
[root@mongodb yum.repos.d]# sudo yum install -y mongodb-org
Loaded plugins: langpacks, ulninfo
mongodb-org-4.4 | 2.5 kB 00:00:00
ol7_UEKR4 | 2.5 kB 00:00:00
ol7_latest | 2.7 kB 00:00:00
mongodb-org-4.4/7Server/primary_db | 47 kB 00:00:02
Resolving Dependencies
--> Running transaction check
---> Package mongodb-org.x86_64 0:4.4.6-1.el7 will be installed
--> Processing Dependency: mongodb-org-shell = 4.4.6 for package: mongodb-org-4.4.6-1.el7.x86_64
...I didn’t need sudo since I was root, but it worked. I don’t know if this was really needed but I set ulimit with these commands:
ulimit -f unlimited
ulimit -t unlimited
ulimit -v unlimited
ulimit -l unlimited
ulimit -n 64000
ulimit -m unlimited
ulimit -u 64000
I am not sure if these commands stick when you run them as root. They seem to but for now I’ve been running them manually after I reboot. These were documented here:
https://docs.mongodb.com/manual/reference/ulimit/
Based on this document I also created the file /etc/security/limits.d/99-mongodb-nproc.conf:
[root@mongodb ~]# cat /etc/security/limits.d/99-mongodb-nproc.conf
* soft nproc 64000
* hard nproc 64000
root soft nproc unlimited
[root@mongodb ~]#
I don’t know for sure if this was needed, but it did not cause any problems.
I edited /etc/selinux/config to prevent SELinux from interfering:
[root@mongodb selinux]# diff config.07012021 config
7c7
< SELINUX=enforcing
---
> SELINUX=disabledI also disabled the firewall just in case it would cause problems:
[root@mongodb ~]# systemctl disable firewalld
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
Removed symlink /etc/systemd/system/basic.target.wants/firewalld.service.
[root@mongodb ~]# systemctl stop firewalld
[root@mongodb ~]# systemctl status firewalld
? firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
...Lastly, in order to be able to access MongoDB from outside the VM I had to edit /etc/mongod.conf to allow access from all IP addresses:
[root@mongodb etc]# diff mongod.conf mongod.conf.07012021
29c29
< bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
---
> bindIp: 127.0.0.1 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
Of course, in a production system you would want to make this more secure, but this is just a quick and dirty test VM.
Finally, this command brings up the database:
systemctl start mongod
I ran this in a new root Putty window to get the ulimit settings. Not sure if that was necessary, but it did work.
I have a NAT network and port forwarding setup so that while MongoDB listens by default on port 27017 host localhost I setup VirtualBox to connect it to port 61029 host 127.0.0.1 on my laptop.
Since the programming language that I am most familiar with is Python (I have not learned any JavaScript) I setup a test connection to my new MongoDB database using the pymongo module.
I installed it like this:
pip install pymongo[srv]Simple test program looks like this:
from pymongo import MongoClient
from pymongo.errors import ConnectionFailure
client = MongoClient('127.0.0.1', 61029)
try:
# The ismaster command is cheap and does not require auth.
client.admin.command('ismaster')
except ConnectionFailure:
print("Server not available")I got that from stackoverflow. I was also following the pymongo tutorial:
https://pymongo.readthedocs.io/en/stable/tutorial.html
One test program:
from pymongo import MongoClient
client = MongoClient('127.0.0.1', 61029)
db = client['test-database']
collection = db['test-collection']
import datetime
post = {"author": "Mike",
"text": "My first blog post!",
"tags": ["mongodb", "python", "pymongo"],
"date": datetime.datetime.utcnow()}
posts = db.posts
post_id = posts.insert_one(post).inserted_id
print(type(post_id))
print(post_id)
print(db.list_collection_names())
import pprint
pprint.pprint(posts.find_one())
pprint.pprint(posts.find_one({"author": "Mike"}))
pprint.pprint(posts.find_one({"author": "Eliot"}))
pprint.pprint(posts.find_one({"_id": post_id}))
post_id_as_str = str(post_id)
pprint.pprint(posts.find_one({"_id": post_id_as_str}))
from bson.objectid import ObjectId
pprint.pprint(posts.find_one({"_id": ObjectId(post_id_as_str)}))
Its output:
<class 'bson.objectid.ObjectId'>
60df400f53f43d1c2703265c
['test-collection', 'posts']
{'_id': ObjectId('60de4f187d04f268e5b54786'),
'author': 'Mike',
'date': datetime.datetime(2021, 7, 1, 23, 26, 16, 538000),
'tags': ['mongodb', 'python', 'pymongo'],
'text': 'My first blog post!'}
{'_id': ObjectId('60de4f187d04f268e5b54786'),
'author': 'Mike',
'date': datetime.datetime(2021, 7, 1, 23, 26, 16, 538000),
'tags': ['mongodb', 'python', 'pymongo'],
'text': 'My first blog post!'}
None
{'_id': ObjectId('60df400f53f43d1c2703265c'),
'author': 'Mike',
'date': datetime.datetime(2021, 7, 2, 16, 34, 23, 410000),
'tags': ['mongodb', 'python', 'pymongo'],
'text': 'My first blog post!'}
None
{'_id': ObjectId('60df400f53f43d1c2703265c'),
'author': 'Mike',
'date': datetime.datetime(2021, 7, 2, 16, 34, 23, 410000),
'tags': ['mongodb', 'python', 'pymongo'],
'text': 'My first blog post!'}
I ran this on Python 3.9.6 so the strings like ‘Mike’ are not u’Mike’. It looks like the output on the tutorial is from some version of Python 2, so you get Unicode strings like u’Mike’ but on Python 3 strings are Unicode by default so you get ‘Mike’.
Anyway, I didn’t get any further than getting MongoDB installed and starting to run through the tutorial, but it is up and running. Might be helpful to someone else (or myself) if they are running through this to setup a test VM.
Bobby
Real World Index Example
This is a follow up to my previous post with a real world example of how much difference indexes can make on tables that do not have them.
I looked at an AWR report of a peak hour on a busy database and noticed sql_id 028pmgvcryk5n:
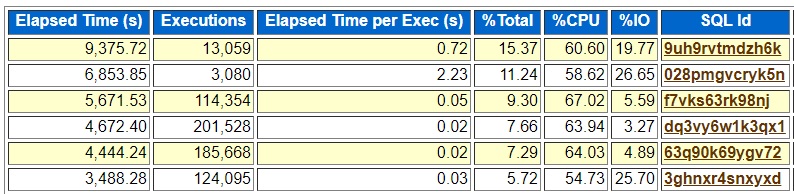 Peak Hour No Indexes
Peak Hour No Indexes
The top SQL is a PL/SQL call so it does not have a plan but 028pmgvcryk5n stood out because it was taking 11.24% of the total elapsed time and running over 2 seconds (2.23) per execution. Most queries on this system run in hundredths of a second like .02 seconds.
I looked at this query’s plan and it included two tables with full scans on both:
I put indexes on each table and the new plan looks like this:
With indexes it ran the query in about 1 millisecond:
Without indexes it ran from 600 to 2000 milliseconds:
I guess I have a simple point. Indexes can make a big difference. A query that runs in 600 milliseconds may be good enough in some cases but if it can run in 1 millisecond it is worth putting on the right indexes.
Bobby
p.s. I used my sqlstat.sql and vsqlarea.sql scripts to get the execution history with and without the indexes. I used getplans.sql to get the plan without indexes from the AWR and extractplansqlid.sql to get the plan with the indexes from the V$ views. The query ran too fast to show up on the AWR once the indexes were in place so that is why I used the V$ queries to get information about the query after adding the indexes.
Simple Index Example
There is a lot to be said about when to add indexes on Oracle tables, but I wanted to show a simple example. In this case we have a table with no indexes and a query with two equal conditions in the where clause which identify a single row out of many. Here is a zip of the SQL*Plus script and log for this post: zip
The table TEST is a clone of DBA_TABLES. I load it up with a bunch of copies of DBA_TABLES and with a single row that is unique. Then I run the query without any indexes on the table:
SQL> select TABLESPACE_NAME
2 from test
3 where
4 owner='TESTOWNER' and
5 table_name = 'TESTTABLE';
TABLESPACE_NAME
------------------------------
TESTTABLESPACE
Elapsed: 00:00:00.15I add an index on owner and table_name and run it again:
SQL> select TABLESPACE_NAME
2 from test
3 where
4 owner='TESTOWNER' and
5 table_name = 'TESTTABLE';
TABLESPACE_NAME
------------------------------
TESTTABLESPACE
Elapsed: 00:00:00.00This may not seem like a big deal going from .15 seconds to .00 seconds (less than .01 seconds). But if you start running a query like this hundreds of thousands of times per hour the .15 seconds of CPU per execution can slow your system down.
See the zip for the details. The create index command looked like this:
SQL> create index testi on test (owner, table_name);
Index created.
Bobby
Fixed Broken Links
I had a couple of new comments on older blog pages and I noticed that some links pointed to things which no longer exist. I fixed a few things that I knew were wrong. Finally, this week I decided to review every post back to the beginning 9 years ago and click on every link.
For dead links I removed the link and added a comment like (DOES NOT EXIST). In some cases, the link still existed but was different. I changed several links to Oracle’s documentation for example. In many cases I put (updated) or something like that to show that there was a new link. I synced up a lot of the old links to the current version of my scripts on GitHub. Hopefully these changes won’t make the older posts unreadable, but at least the links will point to useful and up to date versions of things.
I did not carefully read every post because I was in a hurry, but I did look at every post and it gave me the chance to see how things changed over the past 9 years. It was kind of a quick review of what I was thinking. Some of the posts seemed kind of dumb. (What was I thinking?) But others are genuinely useful. But it was interesting to see which topics I talked about and how that changed over time. It makes me wonder where things will go in the future. I guess I cannot expect to fully predict the future, but it is good to think about what I should be learning and what skills I should be developing as things go forward.
Anyway, hopefully the updated links will make the posts a little more helpful to myself and others.
Bobby
SymPy Tutorial Repository
I have been playing with the Python SymPy package and created a repository with my test scripts and notes:
https://github.com/bobbydurrett/sympytutorial
Might be helpful to someone. I just got started.
I had used Maxima before. SymPy and Maxima are both what Wikipedia calls “Computer Algebra Systems.” They have a nice list here:
https://en.wikipedia.org/wiki/List_of_computer_algebra_systems
I got a lot of use out of Maxima but I think it makes sense to switch the SymPy because it is written in Python and works well with other mainstream Python packages that I use like Matplotlib. They both fall under the SciPy umbrella of related tools so for me if I need some computer algebra I probably should stick with SymPy.
Maxima and SymPy are both free.
Bobby
ORA-14767 when day of month > 28 with interval partitioning month interval
SQL> CREATE TABLE test(
2 RUN_DATE DATE,
3 MY_NBR NUMBER(4)
4 )
5 PARTITION BY RANGE (RUN_DATE)
6 INTERVAL (NUMTOYMINTERVAL(1, 'MONTH'))
7 (
8 PARTITION data_p1 VALUES LESS THAN (TO_DATE('01/29/2017', 'MM/DD/YYYY'))
9 );
CREATE TABLE test(
*
ERROR at line 1:
ORA-14767: Cannot specify this interval with existing high bounds
SQL>
SQL> CREATE TABLE test(
2 RUN_DATE DATE,
3 MY_NBR NUMBER(4)
4 )
5 PARTITION BY RANGE (RUN_DATE)
6 INTERVAL (NUMTOYMINTERVAL(1, 'MONTH'))
7 (
8 PARTITION data_p1 VALUES LESS THAN (TO_DATE('01/28/2017', 'MM/DD/YYYY'))
9 );
Table created.Creating a range partitioned table with a date type partitioning column and a month interval must have a starting partition that has a day < 29 or it gets an ORA-14767 error.
The error message “Cannot specify this interval with existing high bounds” is not helpful. How about something like “Need a day of the month that exists in every month”? February only has 28 days most years so 28 is the max.
Bobby
Free Machine Learning Class from MIT
I noticed this new class from MIT:
It is about machine learning and is free. I think it has some built in exercises with automatic grading but no instructor to interact with.
Since ML is such a hot topic I thought I would share it. I have not taken the class.
Bobby